I have a Mac M1 GPU (macOS 13.5.1, PyTorch 2.0.1) and I’m new to using the M1 GPU for deep learning. I’ve been playing around with the Informer architecture which is the transformer architecture applied to time series forecasting. However, upon changing the device from ‘cuda’ to ‘mps’ in the code, I cannot replicate the example provided by the authors in this google colab notebook. I obtain the same results running with CPU but not with MPS.
As the informer code is more involved, I looked for a simpler example that I’d have problems reconciling with the M1 GPU. The image classification tutorial on PyTorch did not pose an issue. However, this example on sequence to sequence network and attention fails on my M1 GPU. In particular, I get the following result while training the transformer model:
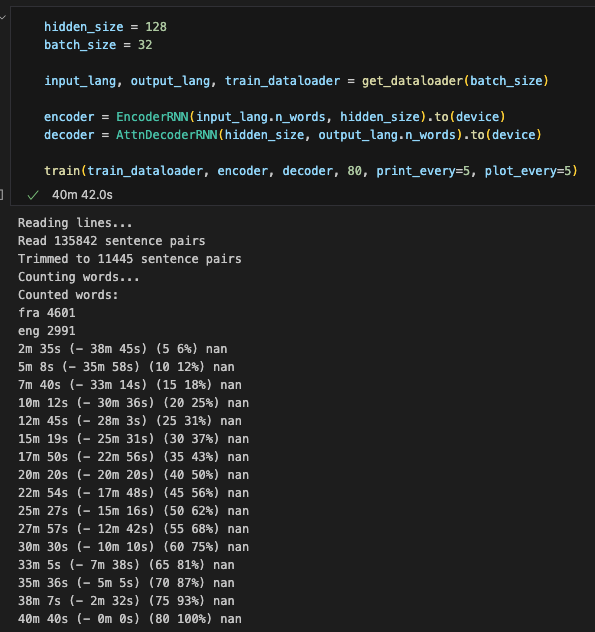
I get nan’s for the loss while the loss gets down to 0.03 in the notebook. (The speed is another issue, unfortunately). The notebook shows a run time of around 6 minutes (CUDA) while it takes 40 minutes on my M1 GPU).
To those who have Mac M1 GPU’s, can you replicate the results in the PyTorch tutorial above? Does anyone know if there is an element of the transformer architecture which is not supported by MPS yet? It doesn’t throw off any errors but I suspect that adjustments have to be made?
Help appreciated!