Hello everyone,
the goal is to use a Transformer as an autoregressive model to generate sequences.
How does the decoder produce the first output prediction, if it needs the output as input in the first place?
That’s like “What came first, the chicken, or the egg”.
My goal is to use a transformer to predict a future vehicle trajectory based on the past vehicle trajectory, not language translation, but I guess that does not change my question.
My Idea would be to cut the last entry of my sequence and use it as the first decoder output. So when the x - coordinate of my vehicle is [3,4,5,6,7] I would chop off the [7] and feed it into the decoder as if it was his prediction. Then continue with regular procedure.
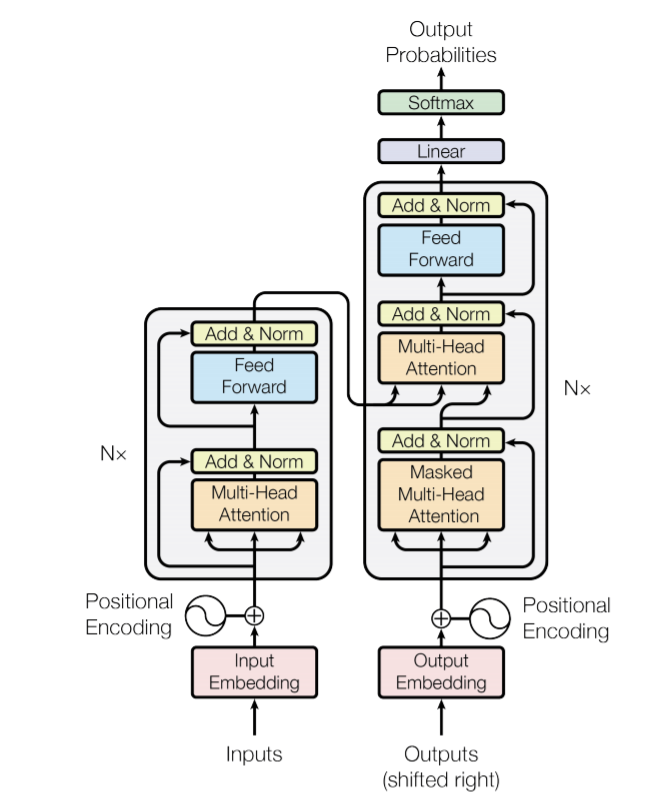
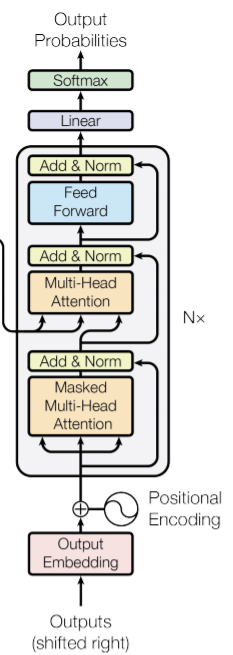
As I mentioned in this post, a special token is usually added at the beginning of the (target) outputs during the training process, and will be used during inference to initialize the output generation (decoding) process, until another special token is produced (marking the end of this decoding process), which has also been added at the end of the target sequences during training.
as far as I understand, the grey cell maintains the shape [batch, sequence, dim] all the way through.
So during infernece, how is last decoder cell supposed to give the probabilities of a single word, if the output shape is [batch, sequence, dim] with sequence > 1 ?
My hypothesis is the following, is that correct?
iteration 1: dec_inp = [start] → dec_out = [y0] append last out element to input (here: y0)
iteration 2: dec_inp = [start, y0] → dec_out = [y0, y1] append last out element to input (here: y1)
iteration 3: dec_inp = [start, y0,y1] → dec_out = [y0, y1,y2]
So you do not actually predict one word, but the whole sequence that you have ‘so far’ and then append the last element of that sequence to the input of the new iteration.
Thanks in advance
I have a question regarding your explanation in the other post:
" With that it will predict the first token (token_1 ) of the output sequence, and the next thing we give to the decoder is: source = encoder_output and target = <BOS> token_1 .
It will output a second token,"
If input [BOS, token_1], the decoder will output also a sequence since every operation in the decoder cells maintains the shape. So how is the decoder output of the shape [batch, sequence, dim] converted into a single “second token” with the shape [batch, 1, dim], as you described? Is the sequence flattened and then the dimension adjusted with a linear layer, or do we simply take the last element of the decoder output as the new token?
In fact, at the beginning of the decoding process, source = encoder_output and target = <BOS> are passed to the decoder and it produces token_1. After source = encoder_output and target = <BOS> token_1 are still passed to the model. The problem is that the decoder will produce a representation of shape [batch_size, 2, embed_dim], which we can then pass to the final classifier to have the output of shape [batch_size, 2, target_vocab_size], but we just select the last word of the seq_len (=2 here) dimension to have a final logits of shape [batch_size, target_vocab_size]. We can just do an argmax (resp. top_k for beam search…) on it (or do softmax before, it doesn’t change much) to get token_2 (resp. ), the index of the second token generated in the vocabulary.
You can ask me why we don’t just pass source = encoder_output and target = token_1 to have outputs logits of shape [batch_size, target_vocab_size] directly. This is usually due to the attention mechanism (here, masked one, because the decoder) : we need to produce a representation of token_1 taking into account all the tokens that precede it (here <BOS>), this representation is finally of shape [batch_size, embedding_dim], which we can just project on the classifier to have [batch_size, target_vocab_size] (if in your classifier you need to look again at the representation of the previous tokens, you can pass [batch_size, seq_len, embedding_dim] to the classifier to have [batch_size, embedding_dim, target_vocab_size] and choose the last token).
And this process continues until the index of the end-of-string symbol is generated
If you know a little bit about tensorflow, you can directly see how they illustrated it here during the validation of their model : Transformer model for language understanding | Text | TensorFlow
In pytorch, the one I use is this one, from facebook research XLM : XLM/transformer.py at master · facebookresearch/XLM · GitHub
There are many implementation of teacher forcing, beam search, … just google