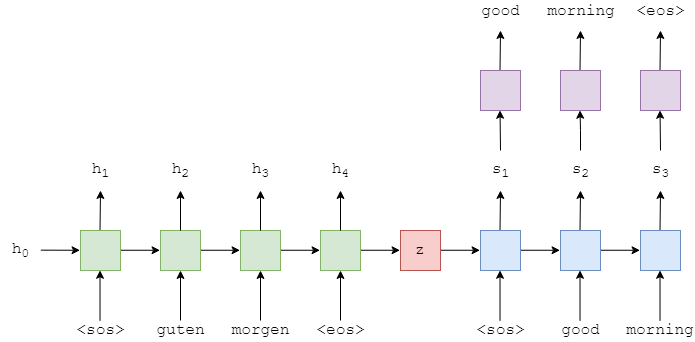
I’m trying to train a Transformer Seq2Seq model using nn.Transformer class. I believe I am implementing it wrong, since when I train it, it seems to fit too fast, and during inference it repeats itself often. This seems like a masking issue in the decoder, and when I remove the target mask, the training performance is the same. This leads me to believe I am doing the target masking wrong. Here is my model code:
class TransformerModel(nn.Module):
def __init__(self, vocab_size, input_dim, heads, feedforward_dim, encoder_layers, decoder_layers, sos_token, eos_token, pad_token, max_len=200, dropout=0.5, device=(torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu"))):
super(TransformerModel, self).__init__()
self.target_mask = None
self.embedding = nn.Embedding(vocab_size, input_dim, padding_idx=pad_token)
self.pos_embedding = nn.Embedding(max_len, input_dim, padding_idx=pad_token)
self.transformer = nn.Transformer(d_model=input_dim, nhead=heads, num_encoder_layers=encoder_layers, num_decoder_layers=decoder_layers, dim_feedforward=feedforward_dim, dropout=dropout)
self.out = nn.Sequential(nn.Linear(input_dim, feedforward_dim), nn.ReLU(), nn.Linear(feedforward_dim, vocab_size))
self.device = device
self.max_len = max_len
self.sos_token = sos_token
self.eos_token = eos_token
def init_weights(self): # Initialize all weights to be uniformly distributed between -initrange and initrange
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def generate_square_subsequent_mask(self, size): # Generate mask covering the top right triangle of a matrix
mask = (torch.triu(torch.ones(size, size)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def forward(self, src, tgt):
# src: (Max source seq len, batch size, 1)
# tgt: (Max target seq len, batch size, 1)
# Embed source and target with normal and positional embeddings
embedded_src = self.embedding(src) + self.pos_embedding(torch.arange(0, src.shape[1]).to(self.device).unsqueeze(0).repeat(src.shape[0], 1))
# Generate target mask
target_mask = self.generate_square_subsequent_mask(size=tgt.shape[0]).to(self.device) # Create target mask
embedded_tgt = self.embedding(tgt) + self.pos_embedding(torch.arange(0, tgt.shape[1]).to(self.device).unsqueeze(0).repeat(tgt.shape[0], 1))
# Feed through model
outputs = self.transformer(src=embedded_src, tgt=embedded_tgt, tgt_mask=target_mask)
outputs = F.log_softmax(self.out(outputs), dim=-1)
return outputs
 . My model seems to be repeating the previous word over and over again
. My model seems to be repeating the previous word over and over again