I am creating a vision transformer for visual odometry. The model I have now is based on the ViViT which is a transformer capable of establishing spatial and temporal relationships.
In training the model is capable of predicting something ( Top image) But when i change the model to eval mode and try to predict on the same data or other similar I only get a straight line (Bottom Image).
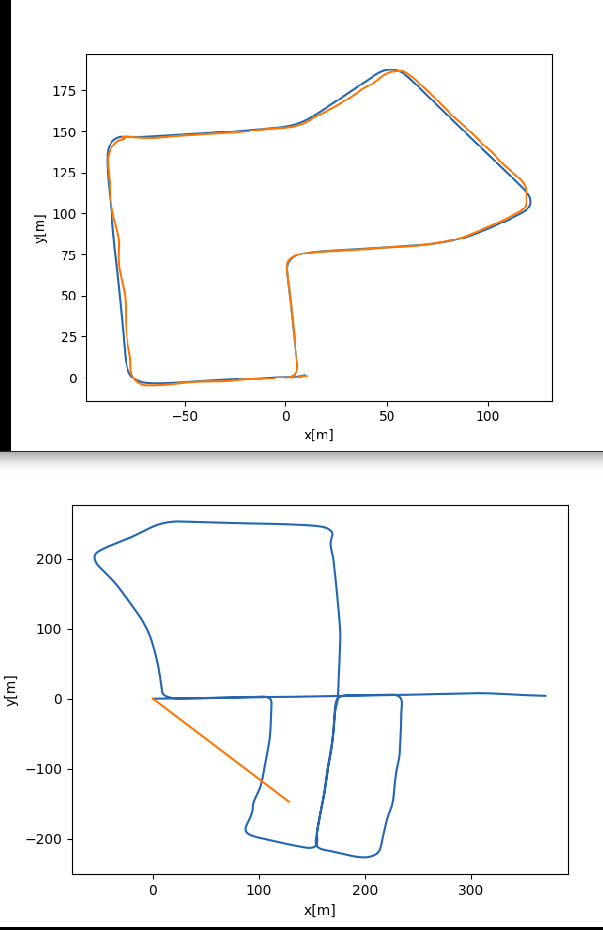
In blue the Ground Truth and in orange the predictions
I stack 2 images on top of each other and feed them to the transformer as seen in the training and test functions
An image as the following format → torch.rand(1, 1, 2, 370, 1241) ↔ (Batches, Channels, NumOfFrames, Height, Width)
for epoch in range(epochs):
### Training
train_loss = 0.0
running_loss = 0.0
loss_values = []
pred_poses = np.empty([len(train_dataset), 3])
pred_poses[0] = train_dataset.getPoses()[0][:, 3:][:3].flatten()
for i in tqdm(range(0, len(train_dataset) - 1)):
imgT = train_dataset[i]["image"].unsqueeze(1)
imgT2 = train_dataset[i + 1]["image"].unsqueeze(1)
imgMerge = torch.cat((imgT, imgT2), dim=1).unsqueeze(0)
optimizer.zero_grad()
with torch.set_grad_enabled(True):
outputs = model(imgMerge) #.cuda()
print("Preds: ", outputs.flatten())
labels = train_dataset[i + 1]["pose"] - train_dataset[i]["pose"]
print("GT Pose: ", labels[:, 3:][:3].flatten())
pred_poses[i + 1] = (np.add(pred_poses[i], outputs[:, :3].cpu().flatten().detach().numpy()))
loss = criterion(outputs, labels)
train_loss += loss
# print(loss)
loss.backward()
optimizer.step()
loss_values.append(loss.item())
train_loss /= len(train_dataset)
print(f"Training Loss: {train_loss:.4f}")
plot_loss(loss_values)
plot_odometry(train_dataset, pred_poses)
### Testing
test_loss = 0.0
running_corrects = 0
test_pred_poses = np.empty([len(test_dataset), 3])
test_pred_poses[0] = test_dataset.getPoses()[0][:, 3:][:3].flatten()
for i in tqdm(range(0, len(test_dataset) - 1)):
imgT = test_dataset[i]["image"].unsqueeze(1)
imgT2 = test_dataset[i + 1]["image"].unsqueeze(1)
imgMerge = torch.cat((imgT, imgT2), dim=1).unsqueeze(0)
# print(imgMerge.shape)
with torch.inference_mode():
outputs = model(imgMerge) #.cuda()
# print(pred_poses)
print(outputs.flatten())
test_pred_poses[i + 1] = (np.add(test_pred_poses[i], outputs[:, :3].cpu().flatten().numpy()))
print("GT: {} | Pred: {}".format(np.array(test_dataset[i + 1]["pose"])[:, 3:][:3].flatten(), test_pred_poses[i + 1]))
# loss = criterion(outputs, dataset[i + 1]["pose"] - dataset[i]["pose"])
# test_loss += loss
# test_loss /= len(dataset)
# running_loss += loss.item() * (poses[i + 1] - poses[i]).size(0)
epoch_loss = running_loss / len(test_dataset)
plot_odometry(test_dataset, test_pred_poses)
And my custom loss function:
def loss_fn(outputs, labels):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
yaw=math.atan2(labels[1][0],labels[0][0])
pitch=math.atan2(-labels[2][0],math.sqrt(labels[2][1]*labels[2][1]+labels[2][2]*labels[2][2]))
roll=math.atan2(labels[2][1],labels[2][2])
translation_loss = torch.nn.functional.mse_loss(labels[:, 3:][:3].to(device).flatten().float(), outputs[:, :3].flatten().float())
rotation_loss = torch.nn.functional.mse_loss(torch.tensor([yaw, pitch, roll]).to(device).float(), outputs[:, 3:].flatten().float())
return translation_loss + rotation_loss * 100
For more context, In eval mode the transformer seems to predict roughly the same values for every single input which doesn’t make much sense to me. Even when the transformer is not trained the output is a straight line. In training this doesn’t happen at all. I also used the architecture I’ve built for video classification and it performed as expected. So I assume the architecture is not the problem…
I can’t figure what is happening and any help is appreciated.