Hi
I am trying to design a transformer model using the nn.TransformerEncoderLayer() and nn.TransformerEncoder() to train in a self-supervised fashion to learn 3D coordinates of skeleton data. The model is as below
Model(
(joint_embedding): embed(
(cnn): Sequential(
(0): norm_data(
(bn): BatchNorm1d(30, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): cnn1x1(
(cnn): Conv2d(3, 8, kernel_size=(1, 1), stride=(1, 1))
)
(2): ReLU()
)
)
(dif_embedding): embed(
(cnn): Sequential(
(0): norm_data(
(bn): BatchNorm1d(30, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): cnn1x1(
(cnn): Conv2d(3, 8, kernel_size=(1, 1), stride=(1, 1))
)
(2): ReLU()
)
)
(attention): Attention_Layer(
(att): ST_Joint_Att(
(fcn): Sequential(
(0): Conv2d(8, 2, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(2, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Hardswish()
)
(conv_t): Conv2d(2, 8, kernel_size=(1, 1), stride=(1, 1))
(conv_v): Conv2d(2, 8, kernel_size=(1, 1), stride=(1, 1))
)
(bn): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): Swish()
)
(pos_encoder): PositionalEncoding(
(dropout): Dropout(p=0.5, inplace=False)
)
(encoder_layer): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=80, out_features=80, bias=True)
)
(linear1): Linear(in_features=80, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=80, bias=True)
(norm1): LayerNorm((80,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((80,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
(transformer): TransformerEncoder(
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=80, out_features=80, bias=True)
)
(linear1): Linear(in_features=80, out_features=2048, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=2048, out_features=80, bias=True)
(norm1): LayerNorm((80,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((80,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
)
)
(mlp_head): Sequential(
(0): LayerNorm((24000,), eps=1e-05, elementwise_affine=True)
(1): Dropout(p=0.5, inplace=False)
(2): Linear(in_features=24000, out_features=2048, bias=True)
(3): ReLU(inplace=True)
(4): Dropout(p=0.5, inplace=False)
(5): Linear(in_features=2048, out_features=512, bias=True)
)
)
I used simclr loss with the augmented sample as positive sample and all other samples in the minibatch as negative samples. Below is the loss curve
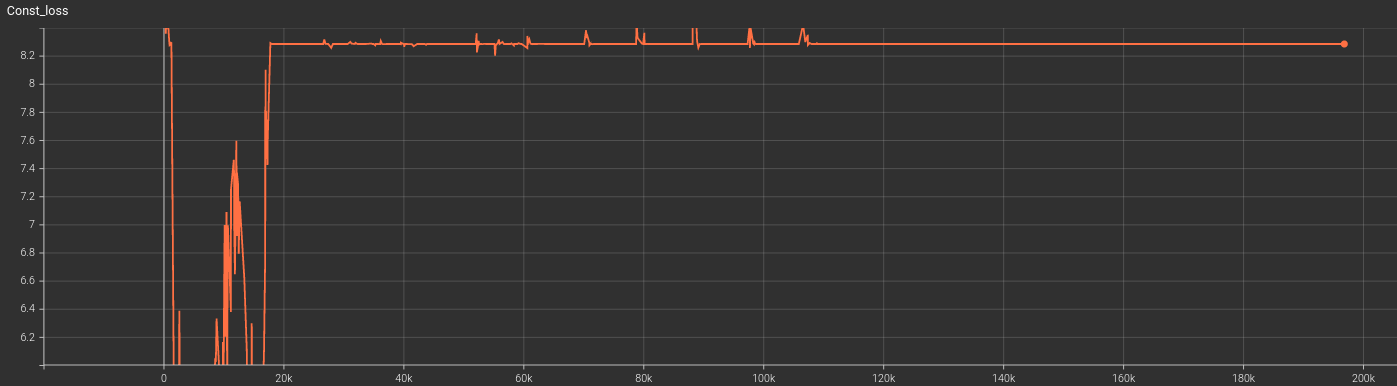
I used learning rate 0.001 with 10% reduction every 10th epoch with a warmup epoch of 100. Below is the learning rates graph
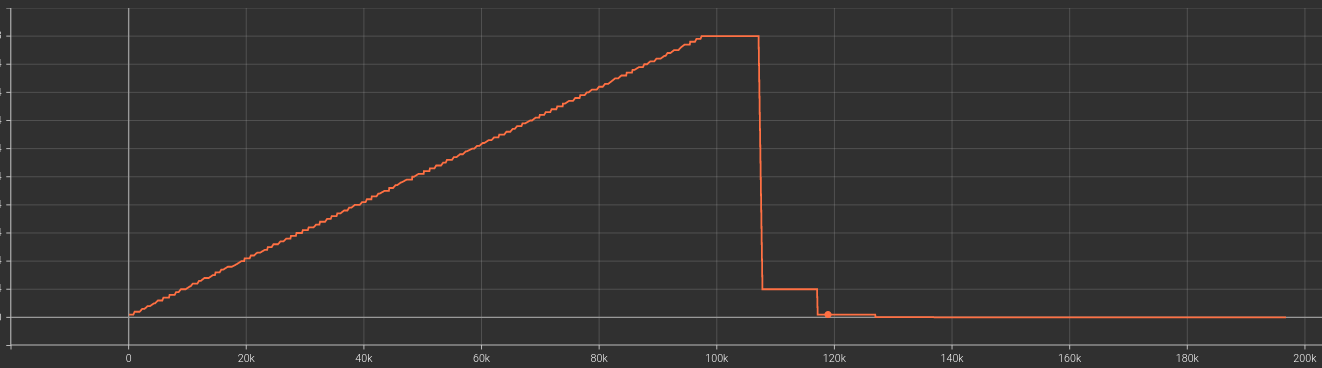
I don’t understand why loss is increasing. Initial input shape: Nx3x300x10 and input to the transformer encoder layer is: Nx300x80
My concerns are
First, my model implementation may be incorrect
Second, maybe the loss function is faulty.
I would really appreciate it if you could suggest what should I appoch.