I have written a transformer model in Pytorch to try to predict crossword answers from clues. I am training it on a dataset of about 200,000 answer-clue pairs. I have tried Adam and SGD optimizers, and am using cross-entropy loss as the cost function.
The model trains well on an artificial dataset with about 100 examples and a simple pattern: the source array is randomly selected from all integers between the minimum and the maximum of the vocabulary tokens, and each element y of the target array is either equal to the corresponding element x, or equal to x+20, or equal to x-20, with some padding and arbitrarily chosen numbers for EOS and SOS tokens. The loss quickly converges to a low value (0.008) from its intial high value, and would probably keep decreasing until approaching zero if the learning rate were lowered.
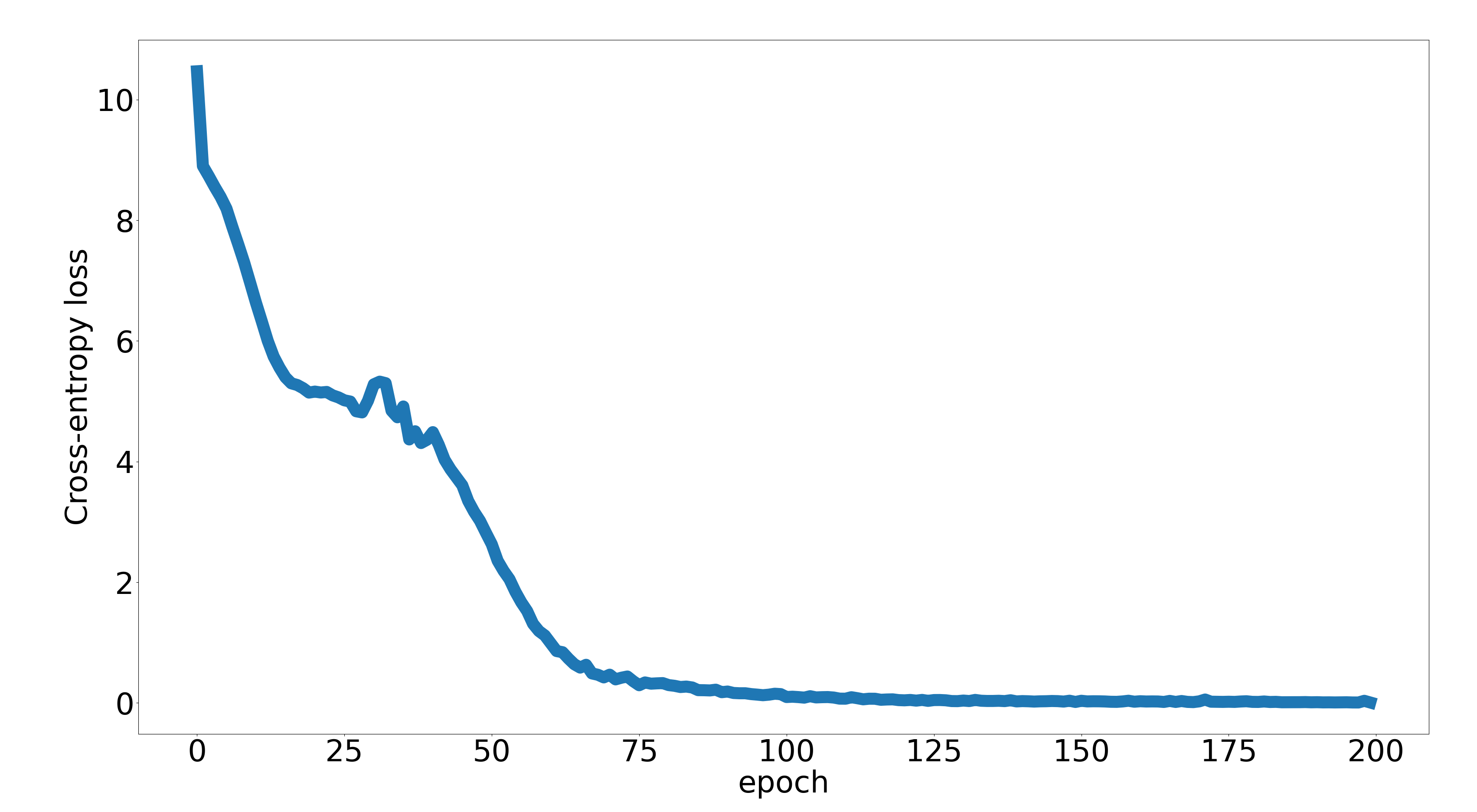
However, it does not train well on the actual dataset. The loss decreases by at most 90%, and then seems to get stuck around a value where the model predicts primarily the first (SOS) token. Its performance on a very small subset of the dataset (say, five items), where we would expect it to overfit, is similarly poor, with the loss function not going below 0.6 even after thousands of epochs:

In conjunction with this, the model tends to disproportionately predict a single value, such as “the,” for all inputs.
Does anyone have any ideas for fixing this?