Hello.
I’m training a transformer to replicate “attention is all you need” for german to english translation and I’ve found that training starts to diverge pretty quickly. I wanted to start with a baseline, so I was following the pytorch transformer tutorial. I.e. the architecture is 2 layers of an encoder, and then the decoder is just a linear layer and a softmax.
Here is an abridged version of the architecture:
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000):
super().__init__()
self.dropout = nn.Dropout(p=dropout)
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, 1, d_model, device=device)
pe[:, 0, 0::2] = torch.sin(position * div_term)
pe[:, 0, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x: Tensor) -> Tensor:
"""
Args:
x: Tensor, shape [seq_len, batch_size, embedding_dim]
"""
# Logic above assumes [seq_len, batch_size, embedding_dim]
# Swap axes for batch_size first, then swap back.
x = torch.swapaxes(x, 1, 0)
x = x + self.pe[:x.size(0)]
x = torch.swapaxes(x, 0, 1)
return self.dropout(x)
class BaselineTransformer(nn.Module):
def __init__(self,
model_dim=512,
nhead=8,
num_encoder_layers=6,
num_decoder_layers=6,
output_vocab_size=10000,
padding_idx=0,
dropout=0.0):
super(BaselineTransformer, self).__init__()
self.model_dimension = model_dim
self.nhead = nhead
self.num_encoder_layers = num_encoder_layers
self.num_decoder_layers = num_decoder_layers
self.output_vocab_size = output_vocab_size
pretrained_model = AutoModelForSeq2SeqLM.from_pretrained("Helsinki-NLP/opus-mt-de-en")
self.encoder_input_embeddings = pretrained_model.get_encoder().embed_tokens.to(device)
self.pos_encoder = PositionalEncoding(model_dim, dropout=dropout)
encoder_layers = TransformerEncoderLayer(d_model=model_dim, nhead=nhead, batch_first=True, dropout=dropout, norm_first=config['norm_first'])
self.transformer_encoder = TransformerEncoder(encoder_layers, num_encoder_layers).to(device)#, encoder_norm).to(device)
self.target_lm_head = nn.Linear(self.model_dimension, self.output_vocab_size, device=device)
self.log_softmax = torch.nn.LogSoftmax(dim=2)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.encoder_input_embeddings.weight.data.uniform_(-initrange, initrange)
self.target_lm_head.weight.data.uniform_(-initrange, initrange)
self.target_lm_head.bias.data.uniform_(math.log(1 / self.output_vocab_size) - initrange, math.log(1 / self.output_vocab_size) + initrange)
def forward(self, source, target, tokenizer,
src_key_padding_mask=None, tgt_key_padding_mask=None, tgt_mask=None, src_mask=None):
source_embeddings_raw = self.encoder_input_embeddings(source) * math.sqrt(self.model_dimension)
source_embeddings = self.pos_encoder(source_embeddings_raw)
memory = self.transformer_encoder(
source_embeddings,
src_key_padding_mask=src_key_padding_mask,
mask=src_mask
)
logits = self.target_lm_head(memory)
res = self.log_softmax(logits)
return res
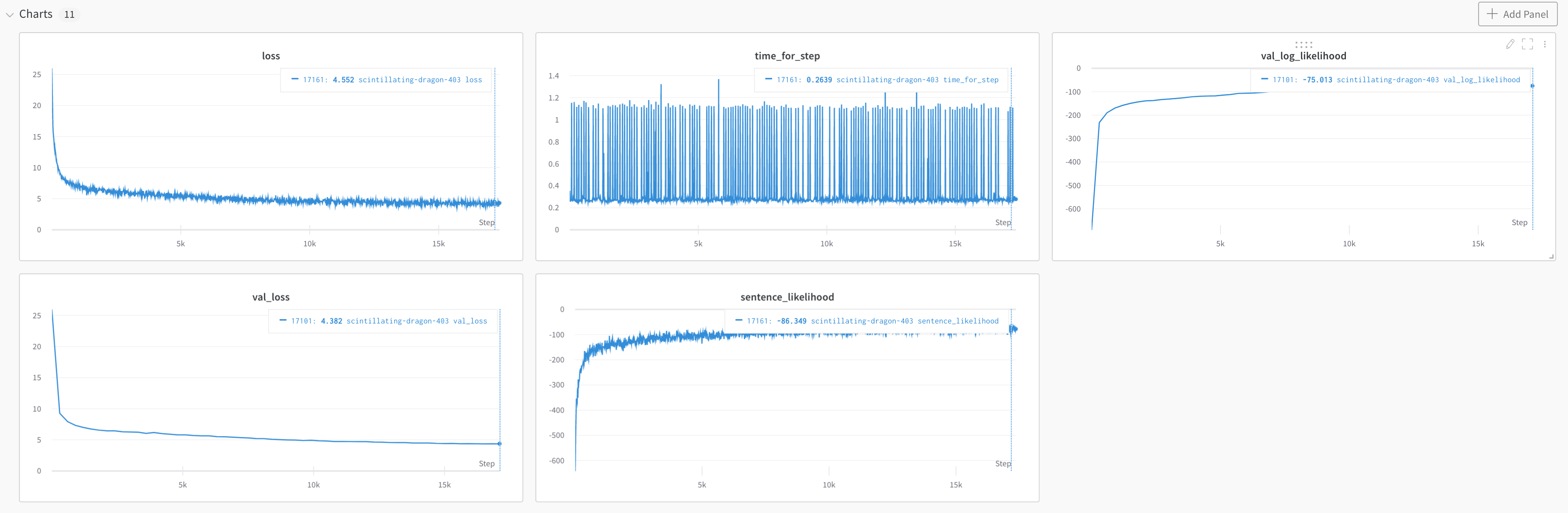
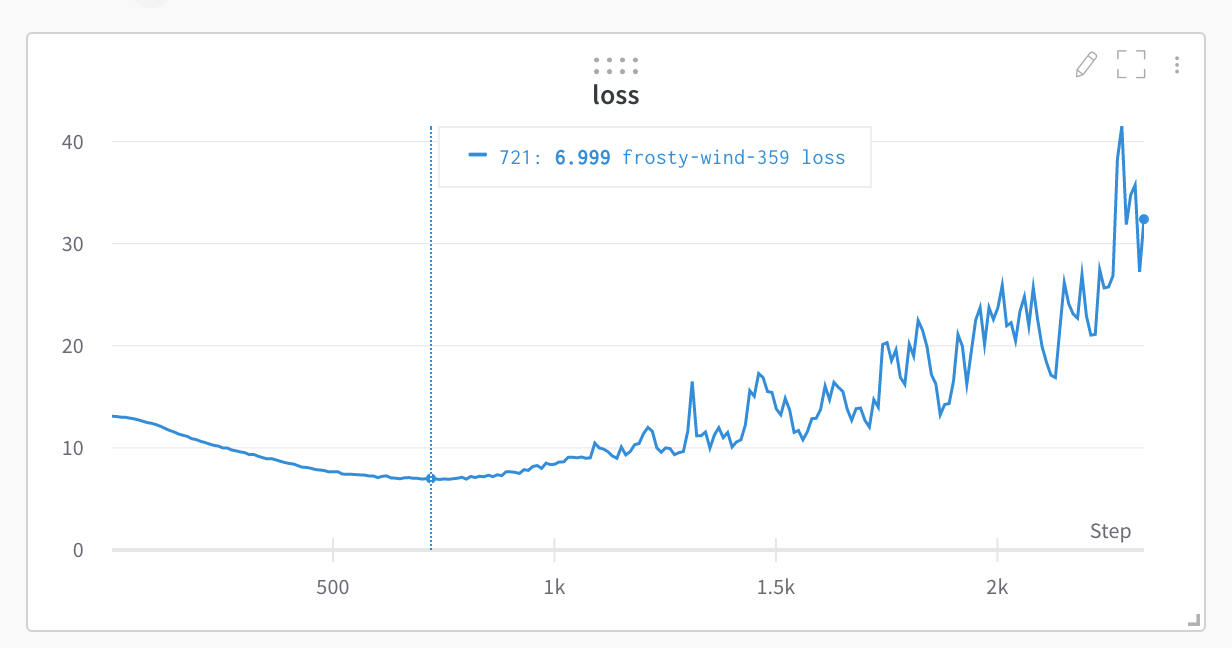
It looks like training loss reaches some low level (≈ 7.5 for NLL) and starts to diverge rapidly thereafter. It also appears as if there is some interaction between the bias of the layer norm and the bias of the attention operation.
Here is the loss: link
Image:
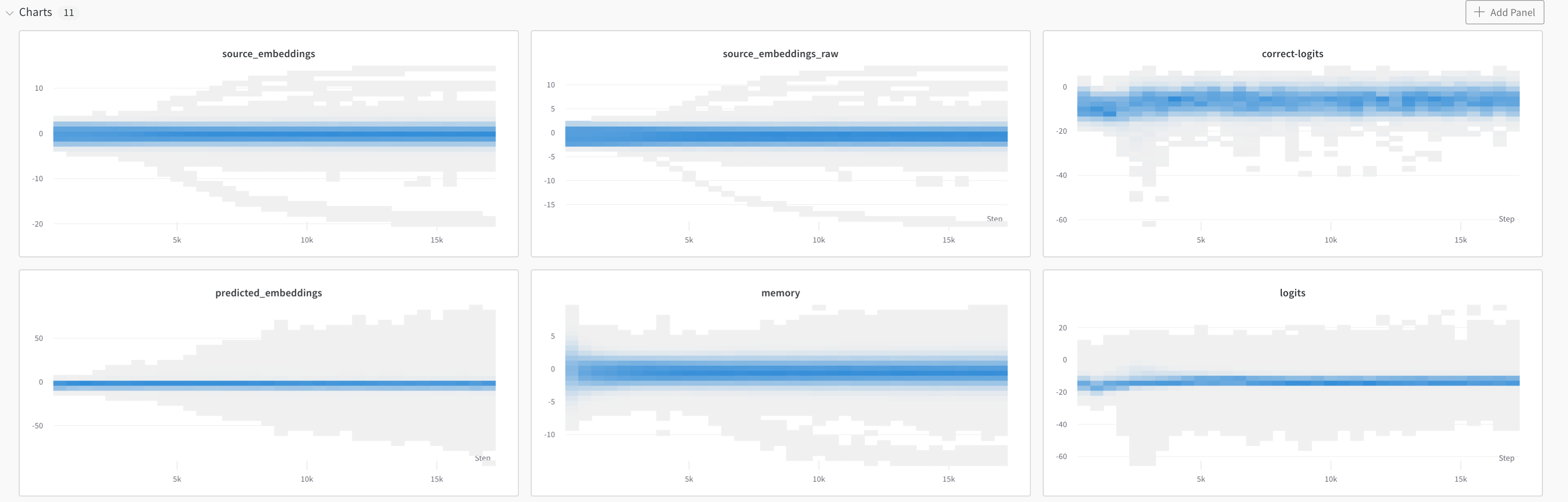
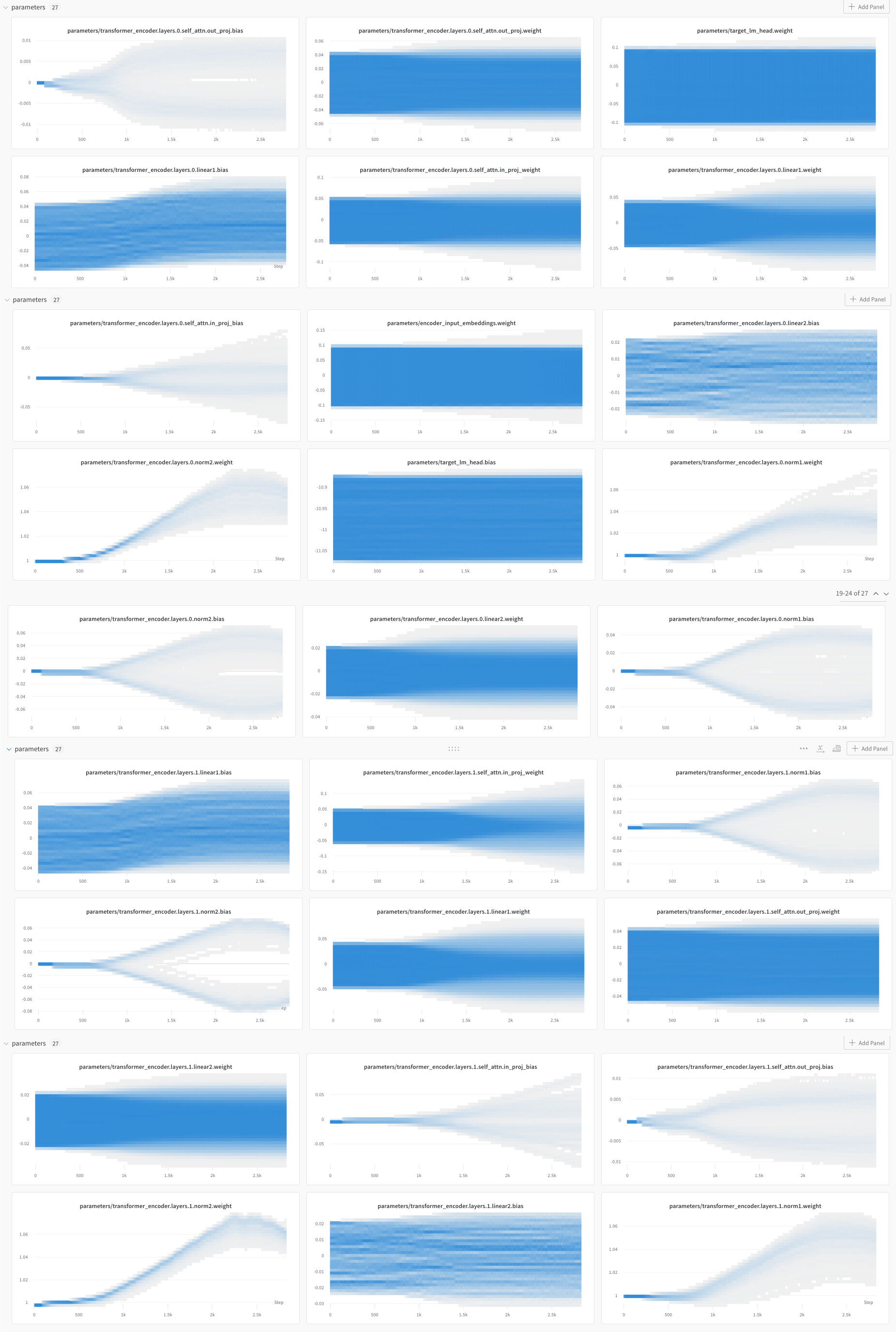
Here are some charts plotting the parameter values evolving over training:
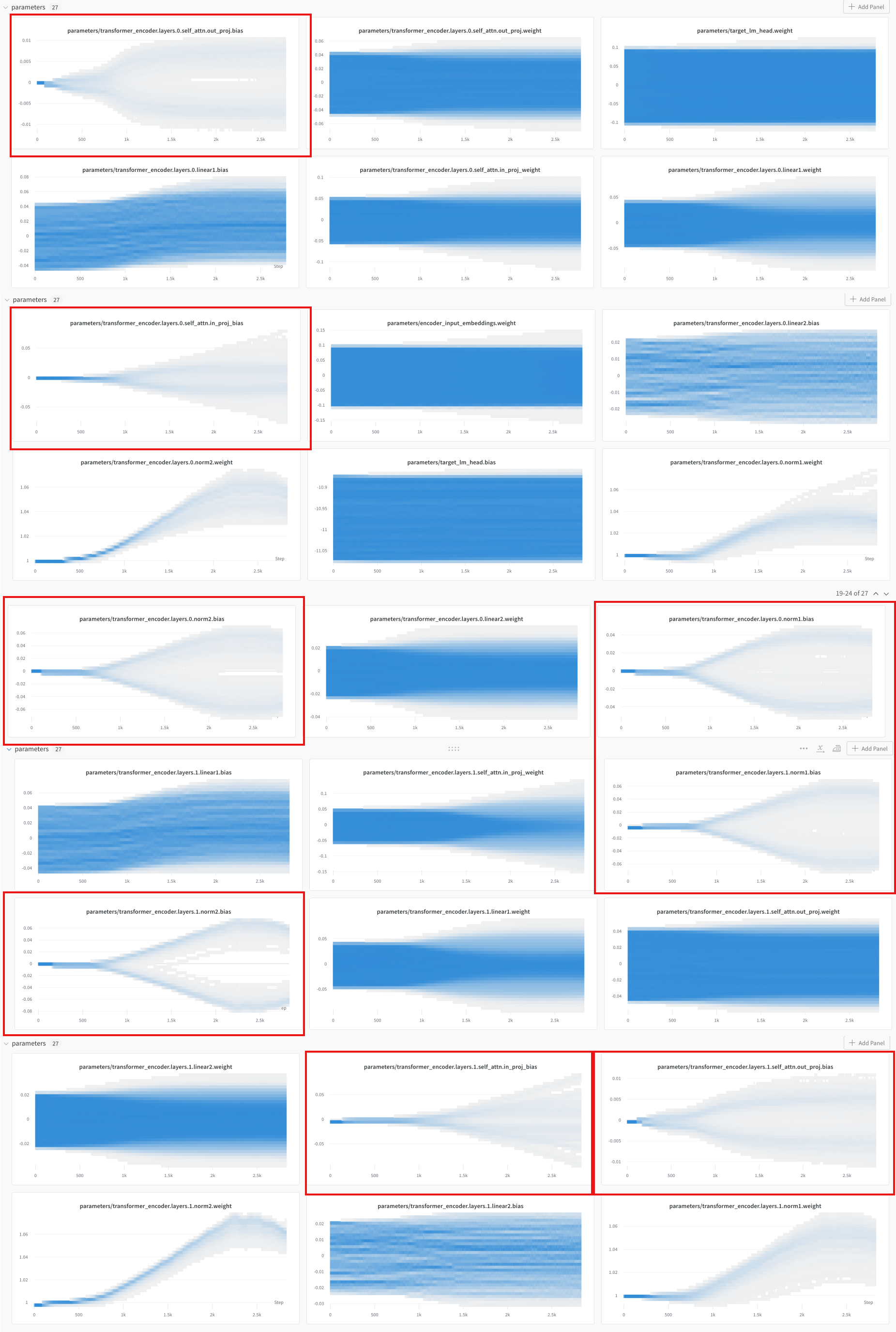
And here are some annotations of the chart that indicate an interaction between norm bias and attention bias (though not positive!)
I’m also using 1/5 the learning rate of the “attention is all you need” paper, so a bit surprised about the training divergence.
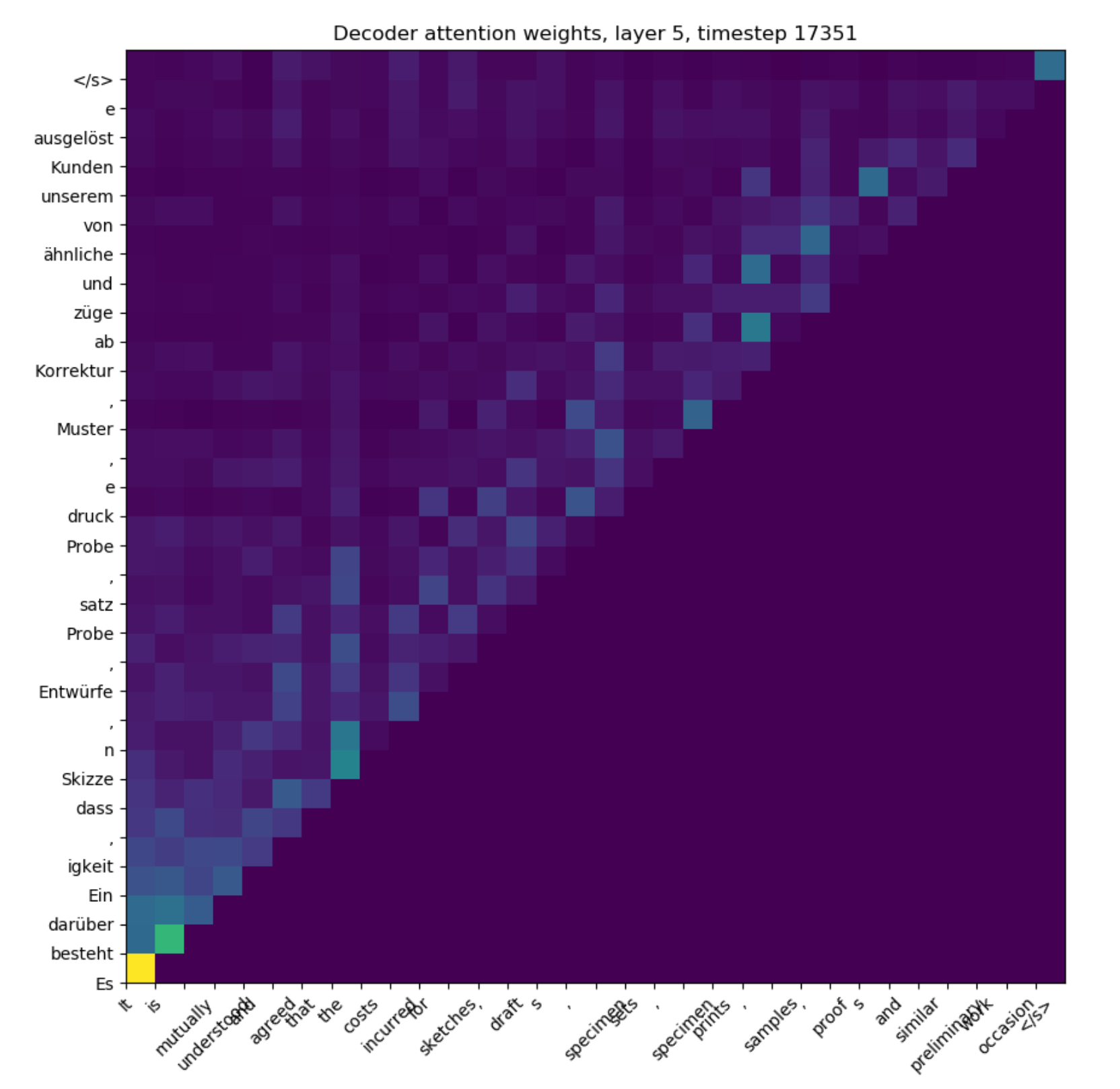
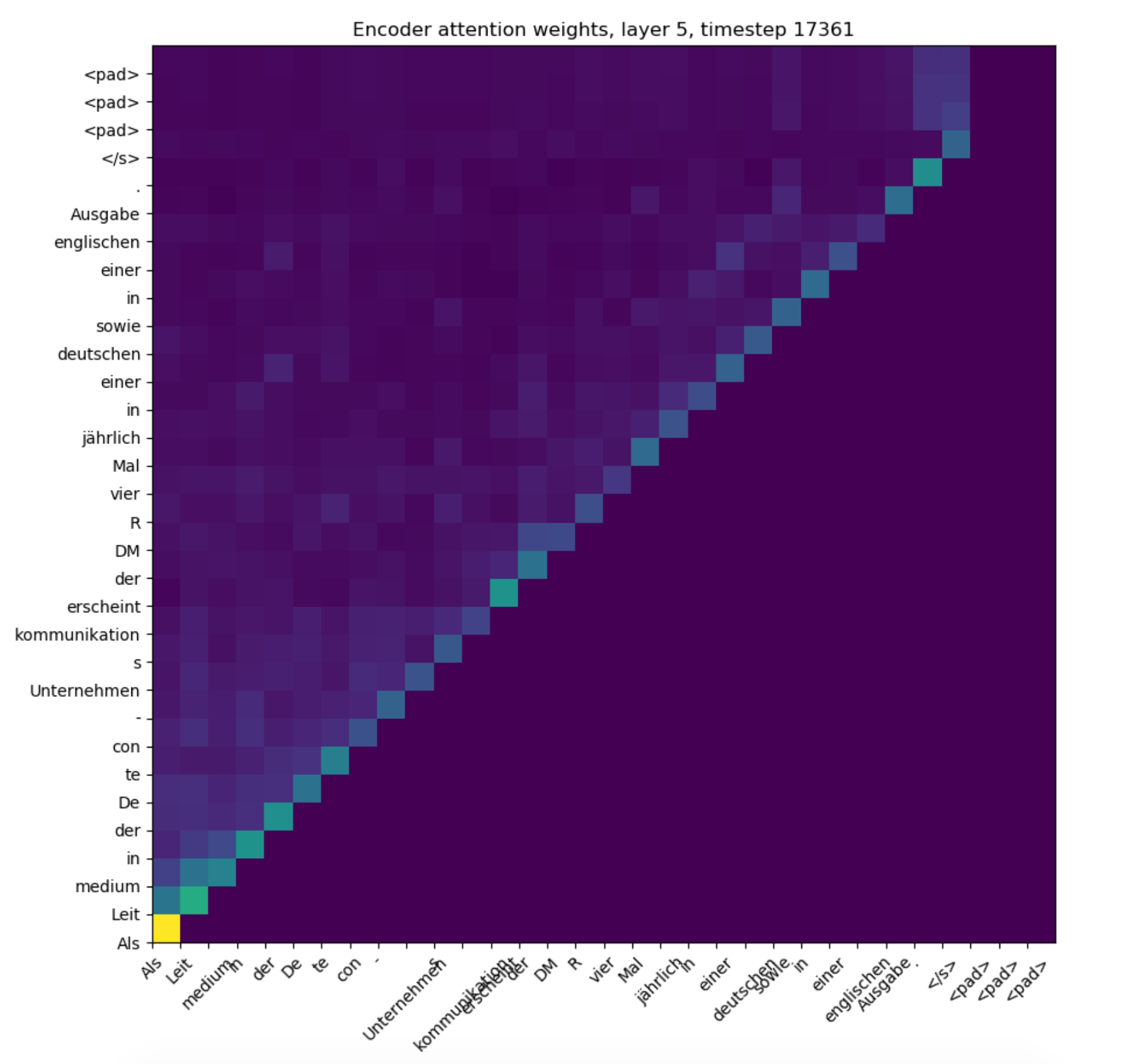
Finally, right around when the divergence starts happening, the attention weights of the first training layer get nuked, and it seems like it just starts paying attention to the same tokens for every other token (note the rows sum to 1 in this heatmap):
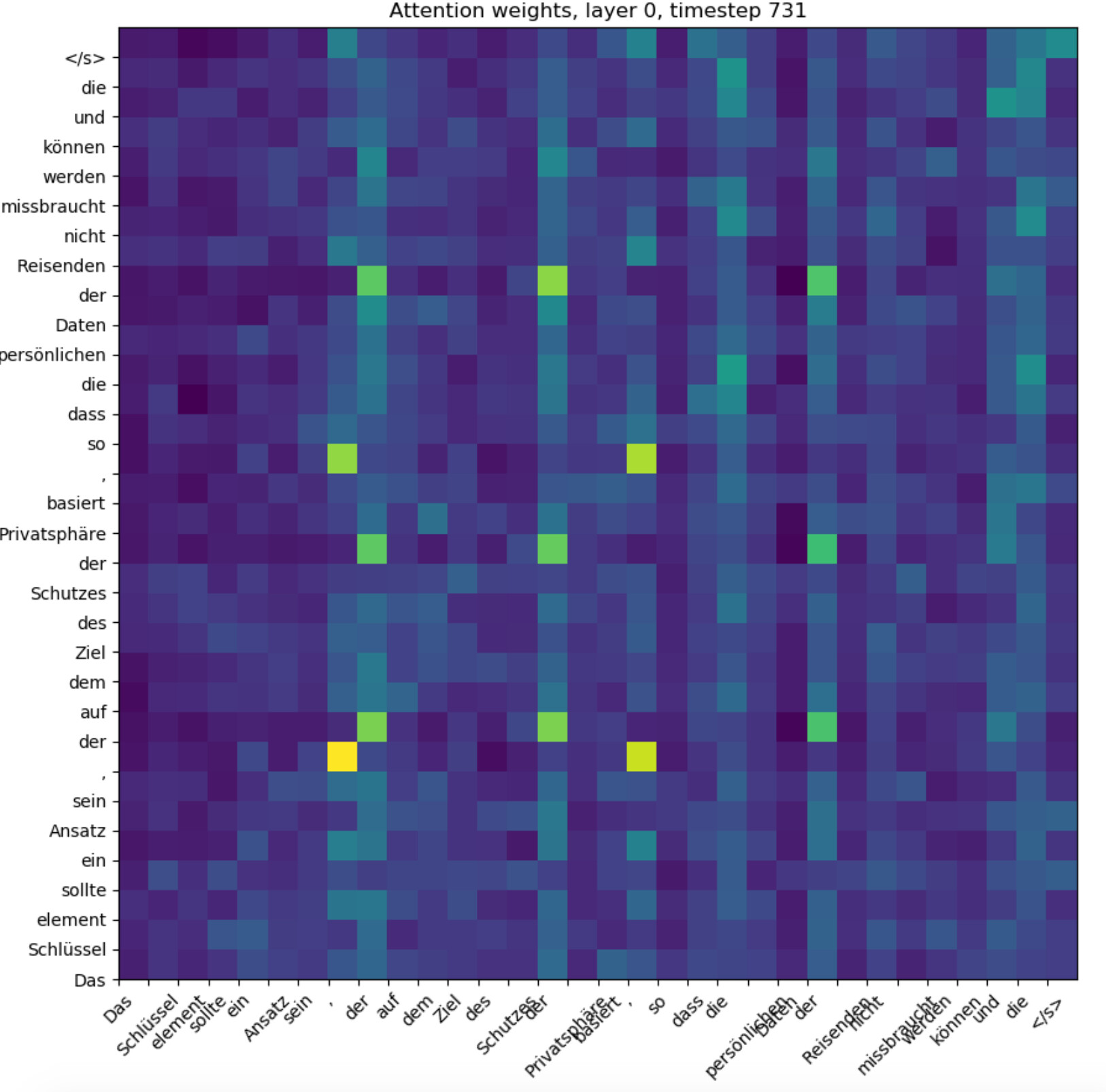


Any idea on what might be happening? This model doesn’t perform much better than an input-independent baseline (which reaches 8.5 NLL whereas this model hits around 7 before diverging).
Also, here’s the hyper parameters used for training in case that helps.