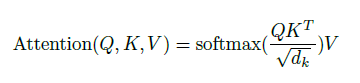What are the differences between Transformer & multi-head self-attention blocks ? I am trying to contextualize sequence of vectors, but not sure which either of the block to use.
Hi,
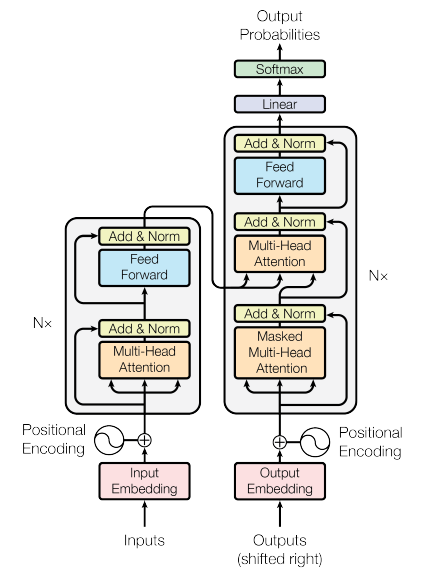
So the Transformer uses multiple Multi-Head Attention (MHA) Blocks. So you are basically using MHA inside the Encoder and the Decoder of the Transformer with other layers such as normalization, skip layers and linear layers.
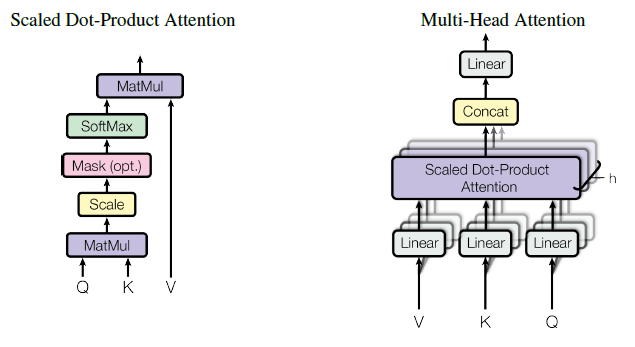
But the MHA is just an operation as shown on the second and third images.
So, depending on your application you might only want to see how the vectors relate to each other with this MHA, or use a more complete approach.
Bert, for example uses only the Encoder part of the Transformer, whereas GPT uses only the Decoder part of the transformer. Vision Transformers also use the Encoder only.
However, since you mention that you want to contextualize vectors, I assume that their position in the sequence matters, so using ONLY MHA will probably be not enough information. Maybe you can use a positional encoding, or simply rely on architectures that already take care of this, such as the already mentioned.
If this is not clear or not what you wanted, please let me know.
Hope this helps ![]()