My model training speed get slower overtime. (first epoch take only 20 minutes but epoch 6 take 50 minutes.
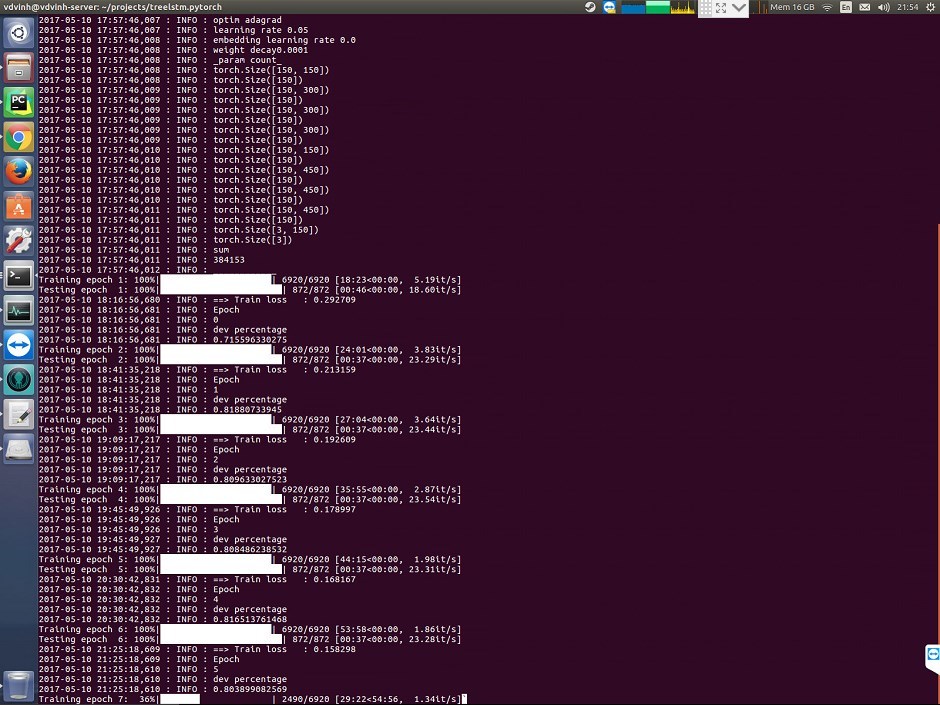
It is train on GPU
Here is the source code with my preprocess sentiment tree bank data
https://drive.google.com/file/d/0B10N16RArpisQ1hPVEdHRXF2UGM/view?usp=sharing
Download http://nlp.stanford.edu/data/glove.840B.300d.zip and put glove.840B.300d.txt into data/glove
Install some python package
pip install meowlogtool
pip install tqdm
Command to run
python sentiment.py --emblr 0 --rel_dim 0 --tag_dim 0 --optim adagrad --name basic --lr 0.05 --wd 1e-4 --at_hid_dim 0
Here is the code on Github for you to read without download (branch pytorch_forum). But I don’t put sst data on github, so you have to download from link above to get data. GitHub - ttpro1995/treelstm.pytorch at pytorch_forum
Model source code
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable as Var
import utils
import Constants
from model import SentimentModule
from embedding_model import EmbeddingModel
class SimpleGRU(nn.Module):
"""
w[i] : (300, 1)
h[i] : (150, 1)
p[i] : (20, 1)
r[i] : (20, 1)
k[i] : (150, 1)
x[i] : (20 + 150 + 300 + 20 = 490, 1) (490, 1)
Uz, Ur, Uh : (150, 150) => 67500 => (450, 450)
Wz, Wr, Wh : (150, 20 + 150 + 300 + 20) (150, 490)
"""
def __init__(self, cuda, in_dim, hid_dim):
super(SimpleGRU, self).__init__()
self.cudaFlag = cuda
self.Uz = nn.Linear(hid_dim, hid_dim)
self.Ur = nn.Linear(hid_dim, hid_dim)
self.Uh = nn.Linear(hid_dim, hid_dim)
self.Wz = nn.Linear(in_dim, hid_dim)
self.Wr = nn.Linear(in_dim, hid_dim)
self.Wh = nn.Linear(in_dim, hid_dim)
if self.cudaFlag:
self.Uz = self.Uz.cuda()
self.Ur = self.Uz.cuda()
self.Uh = self.Uz.cuda()
self.Wz = self.Wz.cuda()
self.Wr = self.Wr.cuda()
self.Wh = self.Wh.cuda()
def forward(self, x, h_prev):
"""
Simple-GRU(compress_x[v], h[t-1]) :
z[t] := s(Wz *compress_x[t]+ Uz * h[t-1] + bz)
r[t] := s(Wr * compress_x[t] + Ur * h[t-1] + br)
h_temp[t] := g(Wh * compress_x[t] + Uh * h[t-1] + bh)
h[t] := r[t] .* h[t-1] + (1 - z[t]) .* h_temp[t]
return h[t]
:param x: compress_x[t]
:param h_prev: h[t-1]
:return:
"""
z = F.sigmoid(self.Wz(x) + self.Uz(h_prev))
r = F.sigmoid(self.Wr(x) + self.Ur(h_prev))
h_temp = F.tanh(self.Wh(x) + self.Uh(h_prev))
h = r*h_prev + (1-z)*h_temp
return h
class TreeSimpleGRU(nn.Module):
def __init__(self, cuda, word_dim, tag_dim, rel_dim, mem_dim, at_hid_dim, criterion, leaf_h = None):
super(TreeSimpleGRU, self).__init__()
self.cudaFlag = cuda
# self.gru_cell = nn.GRUCell(word_dim + tag_dim, mem_dim)
self.gru_cell = SimpleGRU(self.cudaFlag, word_dim+tag_dim, mem_dim)
self.gru_at = GRU_AT(self.cudaFlag, word_dim + tag_dim + rel_dim + mem_dim, at_hid_dim ,mem_dim)
self.mem_dim = mem_dim
self.in_dim = word_dim
self.tag_dim = tag_dim
self.rel_dim = rel_dim
self.leaf_h = leaf_h # init h for leaf node
if self.leaf_h == None:
self.leaf_h = Var(torch.rand(1, self.mem_dim))
torch.save(self.leaf_h, 'leaf_h.pth')
if self.cudaFlag:
self.leaf_h = self.leaf_h.cuda()
self.criterion = criterion
self.output_module = None
def getParameters(self):
"""
Get flatParameters
note that getParameters and parameters is not equal in this case
getParameters do not get parameters of output module
:return: 1d tensor
"""
params = []
for m in [self.gru_cell, self.gru_at]:
# we do not get param of output module
l = list(m.parameters())
params.extend(l)
one_dim = [p.view(p.numel()) for p in params]
params = F.torch.cat(one_dim)
return params
def set_output_module(self, output_module):
self.output_module = output_module
def forward(self, tree, w_emb, tag_emb, rel_emb, training = False):
loss = Var(torch.zeros(1)) # init zero loss
if self.cudaFlag:
loss = loss.cuda()
for idx in xrange(tree.num_children):
_, child_loss = self.forward(tree.children[idx], w_emb, tag_emb, rel_emb, training)
loss = loss + child_loss
if tree.num_children > 0:
child_rels, child_k = self.get_child_state(tree, rel_emb)
if self.tag_dim > 0:
tree.state = self.node_forward(w_emb[tree.idx - 1], tag_emb[tree.idx -1], child_rels, child_k)
else:
tree.state = self.node_forward(w_emb[tree.idx - 1], None, child_rels, child_k)
elif tree.num_children == 0:
if self.tag_dim > 0:
tree.state = self.leaf_forward(w_emb[tree.idx - 1], tag_emb[tree.idx -1])
else:
tree.state = self.leaf_forward(w_emb[tree.idx - 1], None)
if self.output_module != None:
output = self.output_module.forward(tree.state, training)
tree.output = output
if training and tree.gold_label != None:
target = Var(utils.map_label_to_target_sentiment(tree.gold_label))
if self.cudaFlag:
target = target.cuda()
loss = loss + self.criterion(output, target)
return tree.state, loss
def leaf_forward(self, word_emb, tag_emb):
"""
Forward function for leaf node
:param word_emb: word embedding of current node u
:param tag_emb: tag embedding of current node u
:return: k of current node u
"""
h = self.leaf_h
if self.cudaFlag:
h = h.cuda()
if self.tag_dim > 0:
x = F.torch.cat([word_emb, tag_emb], 1)
else:
x = word_emb
k = self.gru_cell(x, h)
return k
def node_forward(self, word_emb, tag_emb, child_rels, child_k):
"""
Foward function for inner node
:param word_emb: word embedding of current node u
:param tag_emb: tag embedding of current node u
:param child_rels (tensor): rels embedding of child node v
:param child_k (tensor): k of child node v
:return:
"""
n_child = child_k.size(0)
h = Var(torch.zeros(1, self.mem_dim))
if self.cudaFlag:
h = h.cuda()
for i in range(0, n_child):
k = child_k[i]
x_list = [word_emb, k]
if self.rel_dim >0:
rel = child_rels[i]
x_list.append(rel)
if self.tag_dim > 0:
x_list.append(tag_emb)
x = F.torch.cat(x_list, 1)
h = self.gru_at(x, h)
k = h
return k
def get_child_state(self, tree, rels_emb):
"""
Get child rels, get child k
:param tree: tree we need to get child
:param rels_emb (tensor):
:return:
"""
if tree.num_children == 0:
assert False # never get here
else:
child_k = Var(torch.Tensor(tree.num_children, 1, self.mem_dim))
if self.rel_dim>0:
child_rels = Var(torch.Tensor(tree.num_children, 1, self.rel_dim))
else:
child_rels = None
if self.cudaFlag:
child_k = child_k.cuda()
if self.rel_dim > 0:
child_rels = child_rels.cuda()
for idx in xrange(tree.num_children):
child_k[idx] = tree.children[idx].state
if self.rel_dim > 0:
child_rels[idx] = rels_emb[tree.children[idx].idx - 1]
return child_rels, child_k
class AT(nn.Module):
"""
AT(compress_x[v]) := sigmoid(Wa * tanh(Wb * compress_x[v] + bb) + ba)
"""
def __init__(self, cuda, in_dim, hid_dim):
super(AT, self).__init__()
self.cudaFlag = cuda
self.in_dim = in_dim
self.hid_dim = hid_dim
self.Wa = nn.Linear(hid_dim, 1)
self.Wb = nn.Linear(in_dim, hid_dim)
if self.cudaFlag:
self.Wa = self.Wa.cuda()
self.Wb = self.Wb.cuda()
def forward(self, x):
out = F.sigmoid(self.Wa(F.tanh(self.Wb(x))))
return out
class GRU_AT(nn.Module):
def __init__(self, cuda, in_dim, at_hid_dim ,mem_dim):
super(GRU_AT, self).__init__()
self.cudaFlag = cuda
self.in_dim = in_dim
self.mem_dim = mem_dim
self.at_hid_dim = at_hid_dim
if at_hid_dim > 0:
self.at = AT(cuda, in_dim, at_hid_dim)
self.gru_cell = SimpleGRU(self.cudaFlag, in_dim, mem_dim)
if self.cudaFlag:
if at_hid_dim > 0:
self.at = self.at.cuda()
self.gru_cell = self.gru_cell.cuda()
def forward(self, x, h_prev):
"""
:param x:
:param h_prev:
:return: a * m + (1 - a) * h[t-1]
"""
m = self.gru_cell(x, h_prev)
if self.at_hid_dim > 0:
a = self.at.forward(x)
h = torch.mm(a, m) + torch.mm((1-a), h_prev)
else:
h = m
return h
class TreeGRUSentiment(nn.Module):
def __init__(self, cuda, in_dim, tag_dim, rel_dim, mem_dim, at_hid_dim, num_classes, criterion):
super(TreeGRUSentiment, self).__init__()
self.cudaFlag = cuda
self.tree_module = TreeSimpleGRU(cuda, in_dim, tag_dim, rel_dim, mem_dim, at_hid_dim, criterion)
self.output_module = SentimentModule(cuda, mem_dim, num_classes, dropout=True)
self.tree_module.set_output_module(self.output_module)
def get_tree_parameters(self):
return self.tree_module.getParameters()
def forward(self, tree, sent_emb, tag_emb, rel_emb, training = False):
# sent_emb = F.torch.unsqueeze(self.word_embedding.forward(sent_inputs), 1)
# tag_emb = F.torch.unsqueeze(self.tag_emb.forward(tag_inputs), 1)
# rel_emb = F.torch.unsqueeze(self.rel_emb.forward(rel_inputs), 1)
# sent_emb, tag_emb, rel_emb = self.embedding_model(sent_inputs, tag_inputs, rel_inputs)
tree_state, loss = self.tree_module(tree, sent_emb, tag_emb, rel_emb, training)
output = tree.output
return output, loss
Thank a lot.