I’m a new learner to deep reinforce learning. In easy task, DRL is easy to converge. If the explore space get more complicated, what tricks or variants I can use to make sure my DRL will converge? Do those variants have the implementations of pytorch?
Prayer? Walking away from it and letting it run for a really long time?
Have you looked at this: http://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html#sphx-glr-intermediate-reinforcement-q-learning-py
Yes, I have read this tutorial before. But I use recurrent PG in task-oriented spoken dialog system. If the behavior of user is much easy, our algorithm is easy to converge. If the behavior of user is more complicated, it seems our algorithm has difficult in learning.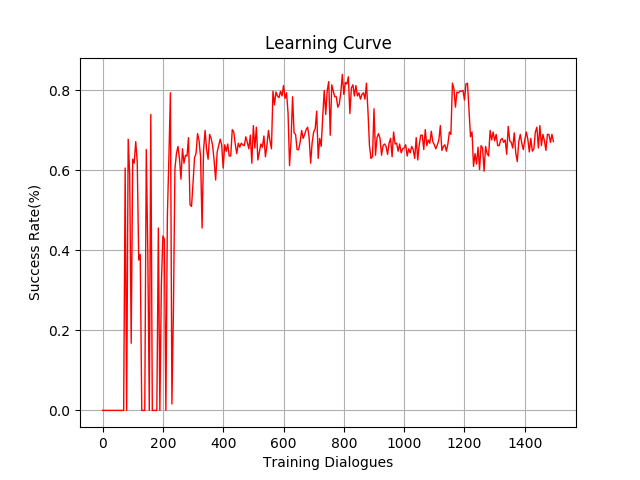
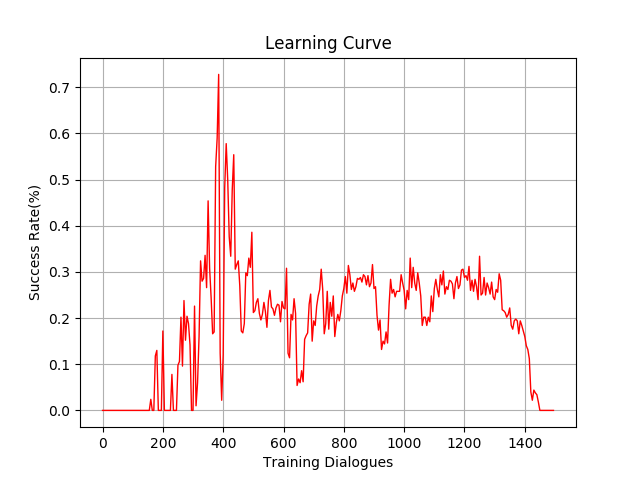
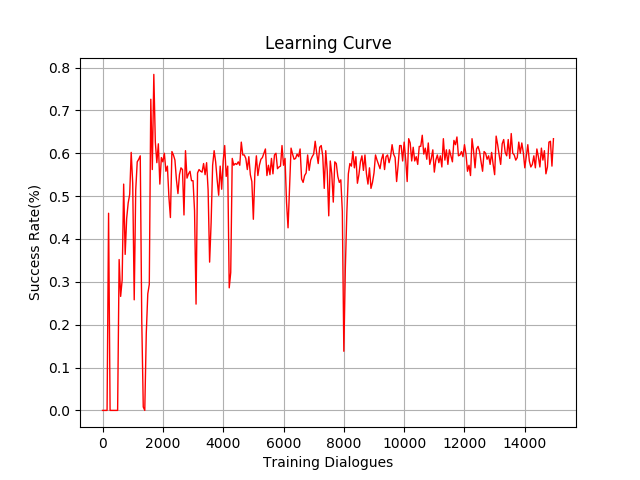
The first figure shows the success rate of simple user, the second and third show the success rate of complicated user. It’s obvious that the same algorithm will be slower to converge in more difficult environment.
What I mean is if there exist some variants of DRL to make sure RL converge faster in complicated environment. And how can I make sure my DRL will do better after one update. In my experiment, I found I can not make sure my RL will get more success rate after one update.
Warning never dabbled on RL yet but my gut feeling would be:
1/ Train on a simpler model, and use the pretrained weights to model more complex behaviour. (Aka fine-tuning, or even curriculum learning)
2/ Try other RL like A3C.
3/ Read Sutton’s RL book
1 Like
Thanks for your reply 
Thank you. I need to learn some tricks of RL. This is really helpful.
1 Like
David Silver’s video lectures and notes are a great reference to get you started