Hi everyone!
I have a problem with training a model.
Here is my train function:
def train(model, optimizer, scheduler, loss_fn, score_fn, epochs, data_tr, data_vl, device):
torch.cuda.empty_cache()
losses_train = []
losses_val = []
scores_train = []
scores_val = []
for epoch in range(epochs):
tic = time()
print('* Epoch %d/%d' % (epoch+1, epochs))
avg_loss = 0
model.train() # train mode
for X_batch, Y_batch in data_tr:
# data to device
X_batch = X_batch.to(device)
Y_batch = Y_batch.to(device)
# set parameter gradients to zero
optimizer.zero_grad()
# forward
print(type(X_batch))
Y_pred = model(X_batch)
#print("Y_pred len: ", Y_pred.size())
#print("Y_batch len: ", Y_batch.size())
loss = loss_fn(Y_pred, Y_batch) # forward-pass
loss.backward() # backward-pass
optimizer.step() # update weights
# calculate loss to show the user
avg_loss += loss / len(data_tr)
toc = time()
print('train_loss: %f' % avg_loss)
losses_train.append(avg_loss)
# train score
avg_score_train = score_fn(model, iou_pytorch, data_tr)
scores_train.append(avg_score_train)
# val loss
avg_loss_val = 0
model.eval() # testing mode
for X_val, Y_val in data_vl:
with torch.no_grad():
Y_hat = model(X_val.to(device)).detach().cpu()# detach and put into cpu
loss = loss_fn(Y_hat, Y_val) # forward-pass
avg_loss_val += loss / len(data_vl)
toc = time()
print('val_loss: %f' % avg_loss_val)
losses_val.append(avg_loss_val)
# val score
avg_score_val = score_fn(model, iou_pytorch, data_vl)
scores_val.append(avg_score_val)
if scheduler:
#scheduler.step(avg_score_val)
scheduler.step()
torch.cuda.empty_cache()
return (losses_train, losses_val, scores_train, scores_val)
Here in this function I move data to GPU
After I move my model also to GPU
unet2_model = UNet2().to(DEVICE)
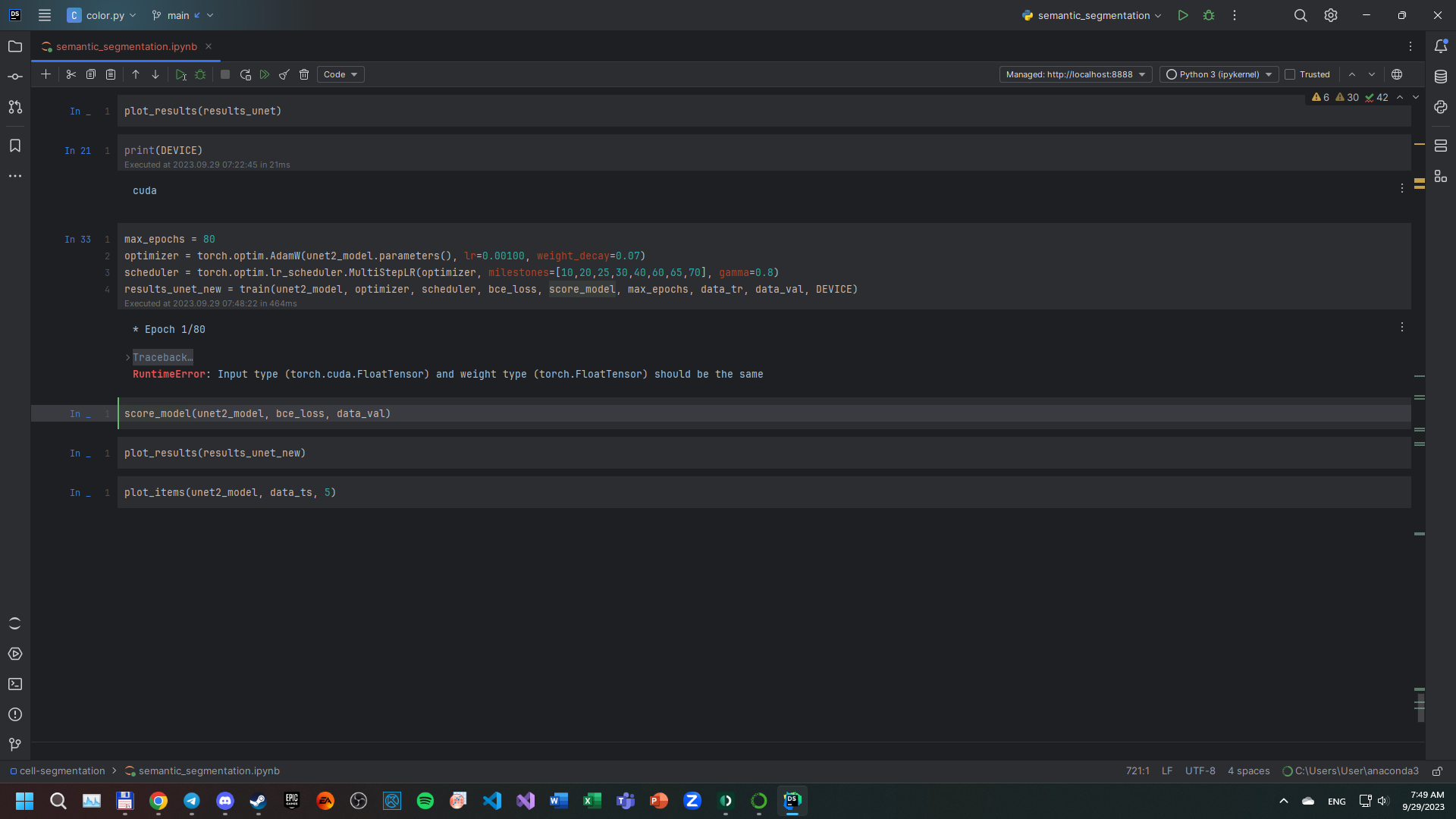
max_epochs = 80
optimizer = torch.optim.AdamW(unet2_model.parameters(), lr=0.00100, weight_decay=0.07)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[10,20,25,30,40,60,65,70], gamma=0.8)
results_unet_new = train(unet2_model, optimizer, scheduler, bce_loss, score_model, max_epochs, data_tr, data_val, DEVICE)
So input and weights have to be on one device (GPU), but I see an error “RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same or input should be a MKLDNN tensor and weight is a dense tensor”
If I don’t move model to GPU, I see an error “Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same”
unet2_model = UNet2()
Can someone explain me why there is a difference in input type when I just change device of model?