Hello, PyTorch community! I would like to inquire about a thread parallelism issue regarding parallel training and validation on the same GPU using two threads.
Here is the basic scenario I am facing: I am training a model in the main thread and saving it after each training epoch. Then, I start a new thread which loads the recently saved model with its weights, and performs validation steps on the same GPU where the model is trained. I hope that since training and validation are on two different threads and they use different CUDA streams, they should be able to execute in parallel, thus reducing the overall training time.
However, the results don’t seem to reflect this. Through PyTorch’s built-in profiler tool, I have found that when both the training and validation threads exist, there still seems to be some sort of “serial ordering” between operations in different CUDA streams. To illustrate this more clearly, here is the profiler result, in different period:
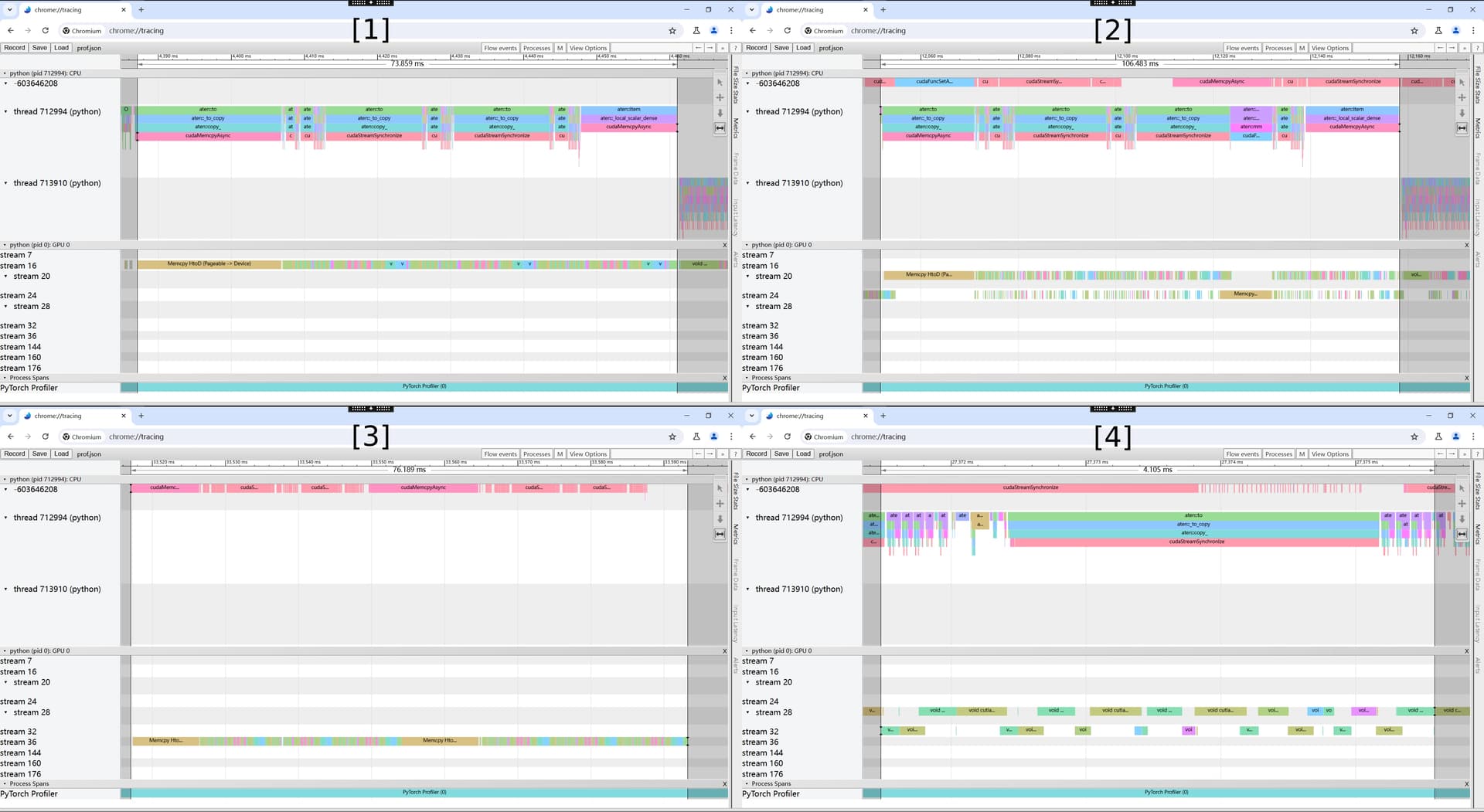
[1]: when only the main thread is training the model
[2]: when two threads are simultaneously training and validating on one GPU
[3]: when the main thread finished model training and only the thread for validation remains
As you can see, the “gaps” between operators within the same CUDA stream in [2] are significantly larger, thus the actual execution time in parallel threads way is almost the same with sequentially execution way.
If we zoom in further on the second image, like [4], it appears that the operations on the two CUDA streams are not executing asynchronously with each other.
I have confirmed that my GPU memory is sufficient to conduct both model training and validation simultaneously (on NVIDIA 3090 and A800, same results). Have I misunderstood something? Is this indeed a feasible method for reducing training time? Thank you in advance!
Here is a summary of my code:
self.thread_pool = ThreadPoolExecutor(max_workers=1)
# Main loop
for _ in range(self.max_epoch):
self._train(train_dataloader)
self._save_model(copy.deepcopy(self.epoch))
self.thread_pool.submit(
self._valid, valid_dataloader, copy.deepcopy(self.epoch)
)
self.epoch += 1
def _train(train_dataloader):
self.model.train()
stream = torch.cuda.Stream()
with torch.cuda.stream(stream):
for idx, (X, y) in enumerate(train_dataloader):
self.optimizer.zero_grad()
X = X.to(self.get_device(), non_blocking=True)
y = y.to(self.get_device(), non_blocking=True)
with autocast():
pred = self.model(X)
loss = self.loss_fn(pred, y)
self.scaler.scale(loss).backward()
self.scaler.step(self.optimizer)
self.scaler.update()
self.scheduler.step()
@torch.no_grad()
def _valid(valid_dataloader, epoch):
model = self._load_model(epoch) # Load recently saved model in this separate thread
model.eval()
stream = torch.cuda.Stream()
with torch.cuda.stream(stream):
for idx, (X, y) in enumerate(valid_dataloader):
X = X.to(self.get_device(), non_blocking=True)
y = y.to(self.get_device(), non_blocking=True)
with autocast():
pred = model(X)
loss = self.loss_fn(pred, y)
Env: PyTorch 2.2.2+cu118