I apologize if this has been asked before, but searching for this is a bit difficult with many people using “deconvolution” for the transposed convolution.
Does PyTorch provide a true deconvolution layer? If not, does anyone have pointers on how to make one from the existing modules/tools? Or is there something that prevents true deconvolution layers from easily being created/used? Thank you for your time!
What do you call a true deconvolution layer? The point of the transposed convolution is to invert the convolution layer, isn’t that what you call true deconvolution?
A true deconvolution would be the mathematical inverse of a convolution. The weights of the deconvolution would accept a 1 x 1 x in_channels input, and output a kernel x kernel x out_channels output.
A transposed convolution does not do this. It performs a ordinary convolution with kernel x kernel x in_channels input to 1 x 1 x out_channels output, but with the striding and padding affecting how the input pixels are input to that convolution such that it produces the same shape as though you had performed a true deconvolution.
While the two approaches produce the same output shape, they produce different results and those results are achieved in very different ways.
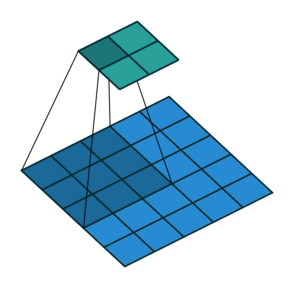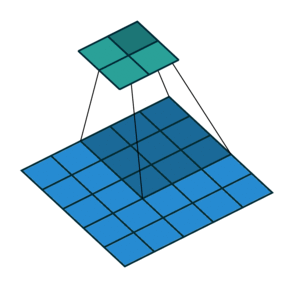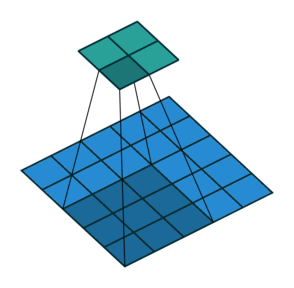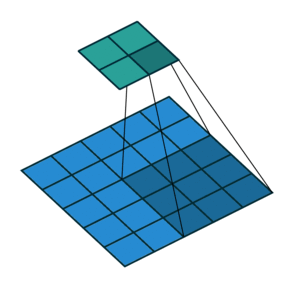
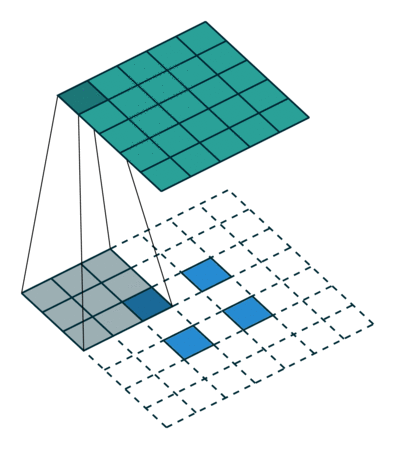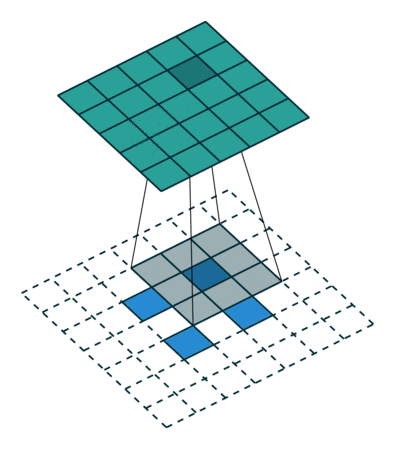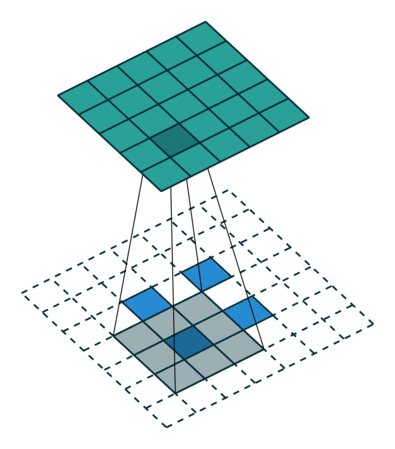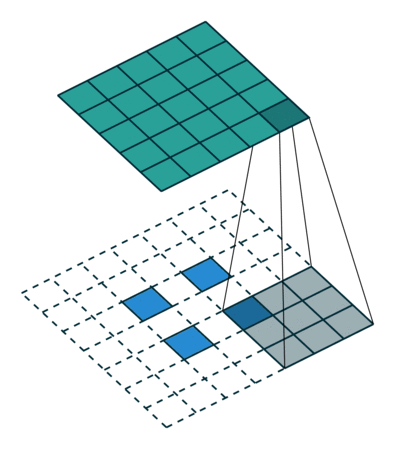
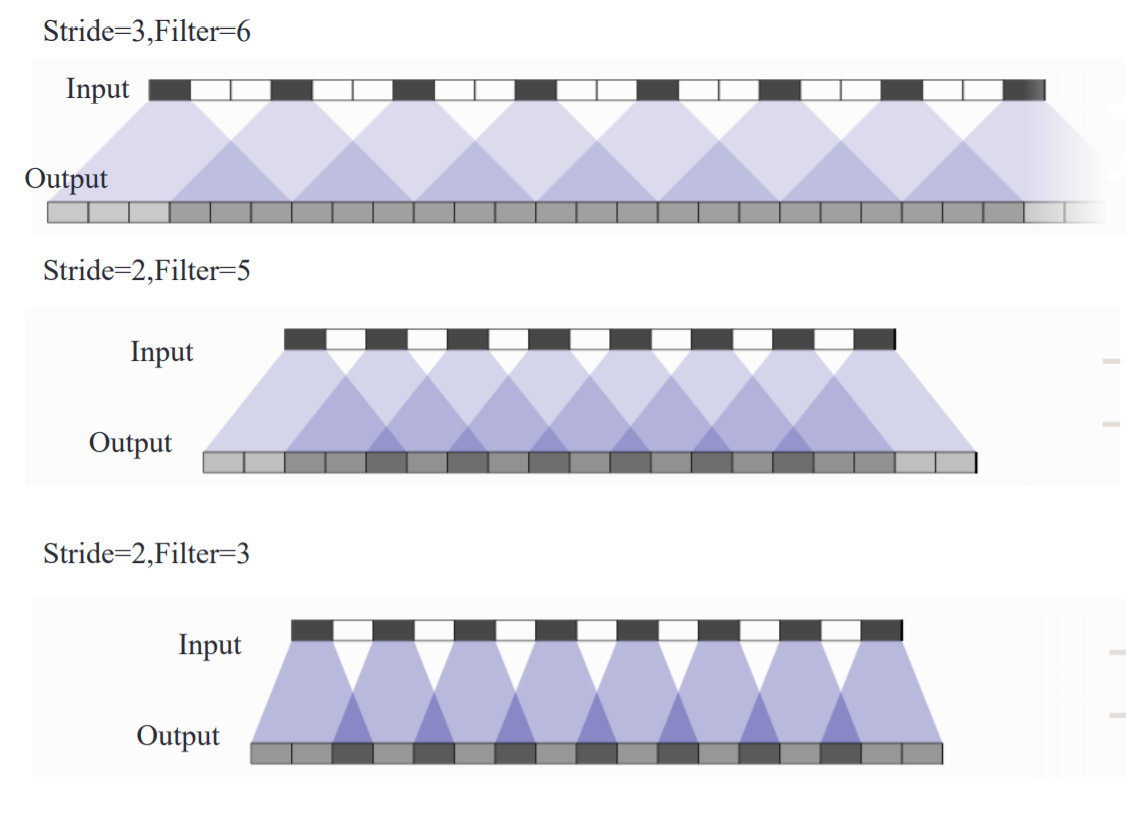
So for convolution of stride 2, with kernel 3x3, from the input blue to the output green, the convolution would look like this:
The true deconvolution would be the exact reverse operation. With the green now being the input, and the blue being the output.
In contrast, the analogous transposed convolution (with stride 2 and kernel 3x3) would spread out the input pixels and apply a regular convolution as shown below (with the input being the blue and the output being the green):
A true deconvolution would be like inverting a Linear layer then?
It would require the operation to be invertible. For a linear, that would be the weight matrix to be definite positive. If your layer reduces the number of dimensions, this is very unlikely.
In general a true deconvolution would not exist for the same reason? Or am I missing something?
In the context of image processing a deconvolution is the inverse of a convolution f = g * h (+ n), i.e. to determine the unknown function g given h and f, while n represents the nosie. One could try to approach this problem with the Fourier transform, as this would yield G = F / H - N / H . However, this will usually enhance the noise term, as the spectrum of the filter H usually flattens for high frequencies, while the noise term still has a lot of power in these frequencies.
There are some other techniques like Wiener deconvolution to counter these noise problems.
Let me know, if I understood your use case right or am completely missing the discussion.
Let me know if I was wrong, I agree with @albanD, how can you invert a convolution operation?
if you have a 2x2 filter with weights w_ij, and input i_ij, the out put would be out_11 = w_11i_11 + w_12i_12+w_21i_21+w_22i_22. How can you calculate i_11~i_22 if you only know out_11 and all filter weights?
I believe in general deep learning frameworks represent convolution operation as matrix multiplication, and that’s why we can use transposed convolution(the transposed matrix multiplication ) as deconvlution.
Sorry, I may have spoken in a misleading way. I am not looking to find the inverse of a specific convolution. I’m looking for a layer which performs the opposite of a convolution layer. That is, a layer which will accept an input of height x width x in_channels, move across each spatial element being accepted as a 1 x 1 x in_channels input, with each of these outputting a kernel x kernel x out_channels patch, and combining those patches to form a final total output. This can of course also be represented as a similar matrix multiplication as the ordinary convolutions. Is there a reason such a layer would not be an option?
[image from http://cvml.ajou.ac.kr/wiki/images/8/83/0_Transposed_convolution.pdf]
Is it the one you are finding?
If it’s the case, we can simulate it simply by using usual convolution with zero padding to its input.
When we denote input as X, kernel as W (with shape 3 X 3), the convolution of X and W as Z,
X[i][j] contribute Z[i][j] with weight W[1][1], Z[i-1][j-1] with weight W[0][0], …, etc.
You’re right. You can achieve equivalent results using the transposed convolution.
Interestingly, the image you provided illustrates the transposed convolution using deconvolutions instead of how the transposed convolution actually operates (with the kernel size being applied to the input, not the output). The effect is the same, but the actual process is different. To me, that deconvolution point of view makes more sense (and I assume it makes more sense to others as well, since that’s how they’re illustrating it in their explanation). And further, I think it would require less calculations (since you’re not constantly inputting a bunch of padding zeros into your convolutions). Is there a reason why the implementation is performed this way rather than as a deconvolution?
That is, with the transposed convolution, you’re moving the kernel over the input. If the striding is the same as the kernel size, then for each kernel x kernel size patch of output, you are only using one spatial input element. However, you need to perform the convolution for this one spatial input element kernel x kernel times. That is, placing that element at each possible position in the convolution to get the kernel x kernel outputs. However, if it was performed as a deconvolution, it would be a single deconvolution. You would have the same number of weights but no padding would be used in the deconvolution and so all the calculations would be done at once. Is there some reason this option isn’t available or isn’t more efficient? Am I missing something else?
Hi, the paper (P17) said “Doing so is inefficient and real-world implementations avoid useless multiplications by zero, but conceptionally it is how the transpose of a strided convolution can be thought of”.
There is a difference between these two methods, because when we “merge” deconvolution results of all pixels, there can be max, mean (neglecting zero), sum and etc.
But transposed convolution method is only equivalent to sum, which might not be desirable since the number of pixel contributing to a result pixel is changing, which will lead to a “non-uniform” result.