In order to back-propagate you need the output and the target. Both of them are kept for the last k1 steps.
outputs.append(output)
targets.append(target)
while len(outputs) > self.k1:
# Delete stuff that is too old
del outputs[0]
del targets[0]
As you may see at the gif I posted, for the rest (k2-k1) steps the output is not requered.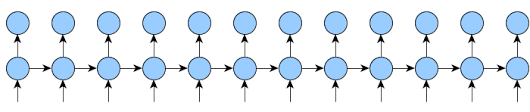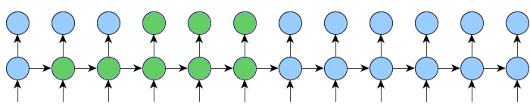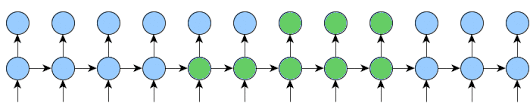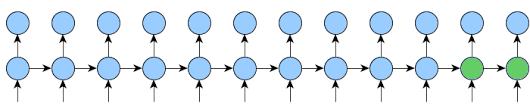
The inp you are referring to is already saved into each state, as part of the graph that torch automatically creates and thats why the k2 last states are kept.
states.append((state, new_state))
while len(states) > self.k2:
# Delete stuff that is too old
del states[0]
This implementation do whats exactly denoted on this paper(section 4) as BPTT(h; h’), where h’=k1 and h=k2.