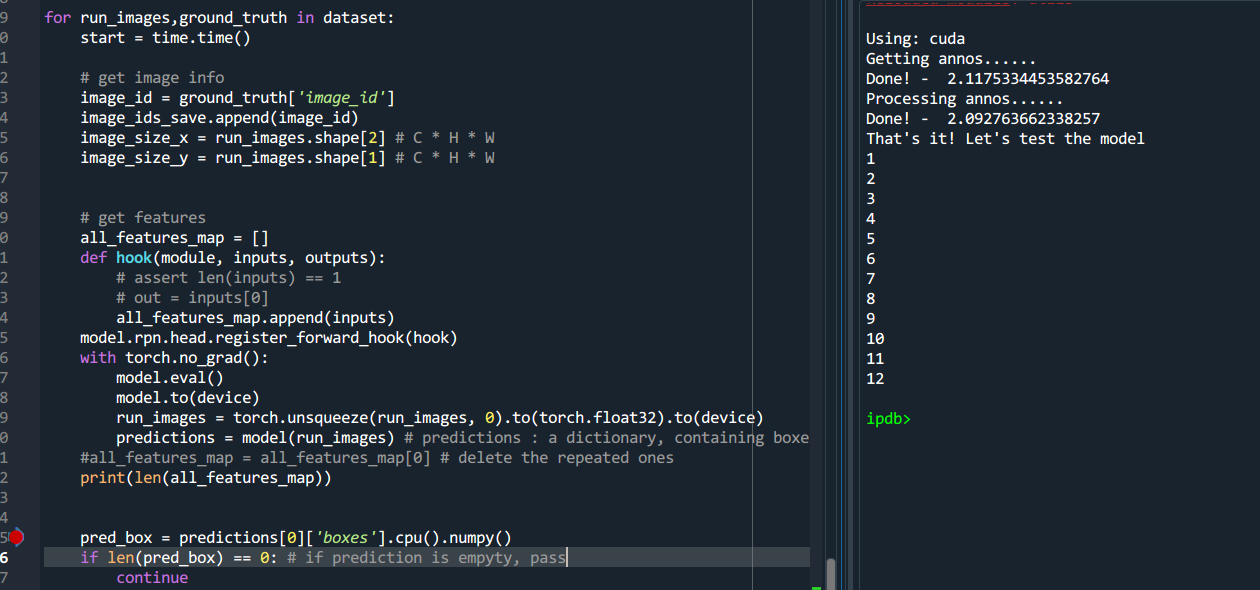
I’m work on KeypointRCNN, and I try to get the outputs of the FPN(feature maps), so I use “register_forward_pre_hook” like this:
for name, m in model.named_modules(): **
** if name ==‘rpn.head’:
** m.register_forward_pre_hook(get_layer)**
Where “get_layer” is a function saving the rpn.head’s input,which is the output of FPN(I guess):
def get_layer(module, x): **
** all_features_map.append(x)
Thanks to the poor memory of my 1050Ti GPU, I can only run one image each time, so I try this:
for run_images , target in dataset:
** with torch.no_grad():**
** model.eval()**
** model.to(‘cuda’)**
** run_images = torch.unsqueeze(run_images, 0).to(torch.float32).to(device)**
** predictions = model(run_images) **
** …**
However! I find that the dim[0] of outputs I get from “get_layer”, are linearly increasing.
The first image,I get 1280,which is 256*5, well, it’s nice, but the next time I get 2560, and 3840 and so forth.
I guess it’s due to for some reason, when I use “for”, the forward() function will somehow invoke more times.
So I try to wrap this whole operation mentioned before as a function “get_feat”, I find that by this way, the dim[0] of features are always 1280, which is nice I guess.
for i in range(40):
** f,p,g = get_feat(i)**
** feat_set_save.append(f)**
** pos_set_save.append(p)**
** gt_set_save.append(g)**
** torch.cuda.empty_cache()**
However! For some unknown reasons, this way may require more memory, I meet “CUDA out of memory” every time when I run about 25 images this function. Actually I think it’s not my GPU’s problem,for the reason that when I didn’t warp this operation as a function, I have already run 1000 images(Although the features are wrong).
Can u give me some advice? Thank u so much!!!