the library i used is same as below:
from distributed import apply_gradient_allreduce
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data import DataLoader
my init_distributed function is following:
def init_distributed(args, n_gpus, rank, group_name):
assert torch.cuda.is_available(), “Distributed mode requires CUDA.”
print(“Initializing distributed”)
# Set cuda device so everything is done on the right GPU.
torch.cuda.set_device(rank % torch.cuda.device_count())
# Initialize distributed communication
torch.distributed.init_process_group(
backend=args.dist_backend, init_method=args.dist_url,
world_size=n_gpus, rank=rank, group_name=group_name)
print(“Done initializing distributed”)
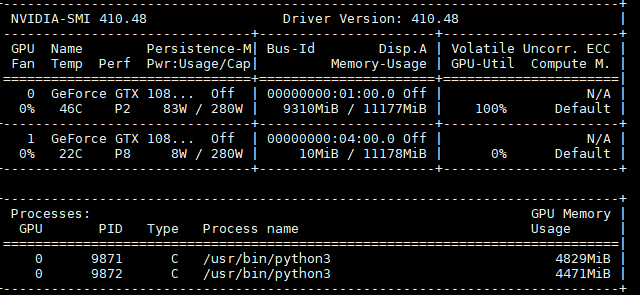
when I make a training but the code works on only one gpu with two processes.
How can I fix this problem?