I have a very simple discriminator for a toy GAN problem where I’m trying to find the magnitude of the gradient in order to apply a penalty to the gradient. In order to do that, I need the gradient norm to be differentiable.
When I calculate the loss function for the generator I get the following computational graph:
# This code produces a tensor with a GradFn
bce = -1 * d_z.mean()
And then when I differentiate the loss with respect to the parameters I get a valid graph:
# This code produces a tensor with a GradFn
gradient = grad(bce, gan.G.parameters(), retain_graph=True, create_graph=True)
Here is the code for the generator:
class Linear(nn.Module):
def __init__(self, in_features: int, out_features: int):
super(Linear, self).__init__()
self.W = nn.Linear(in_features, out_features)
def forward(self, x: Tensor) -> Tensor:
return self.W(x)
Now… when I do the same thing for the discriminator, it doesn’t work. The loss works fine:
# This code produces a tensor with a GradFn
d_x = gan.D(X)
d_z = gan.D(g_X.detach())
bce = d_z.mean() - d_x.mean()
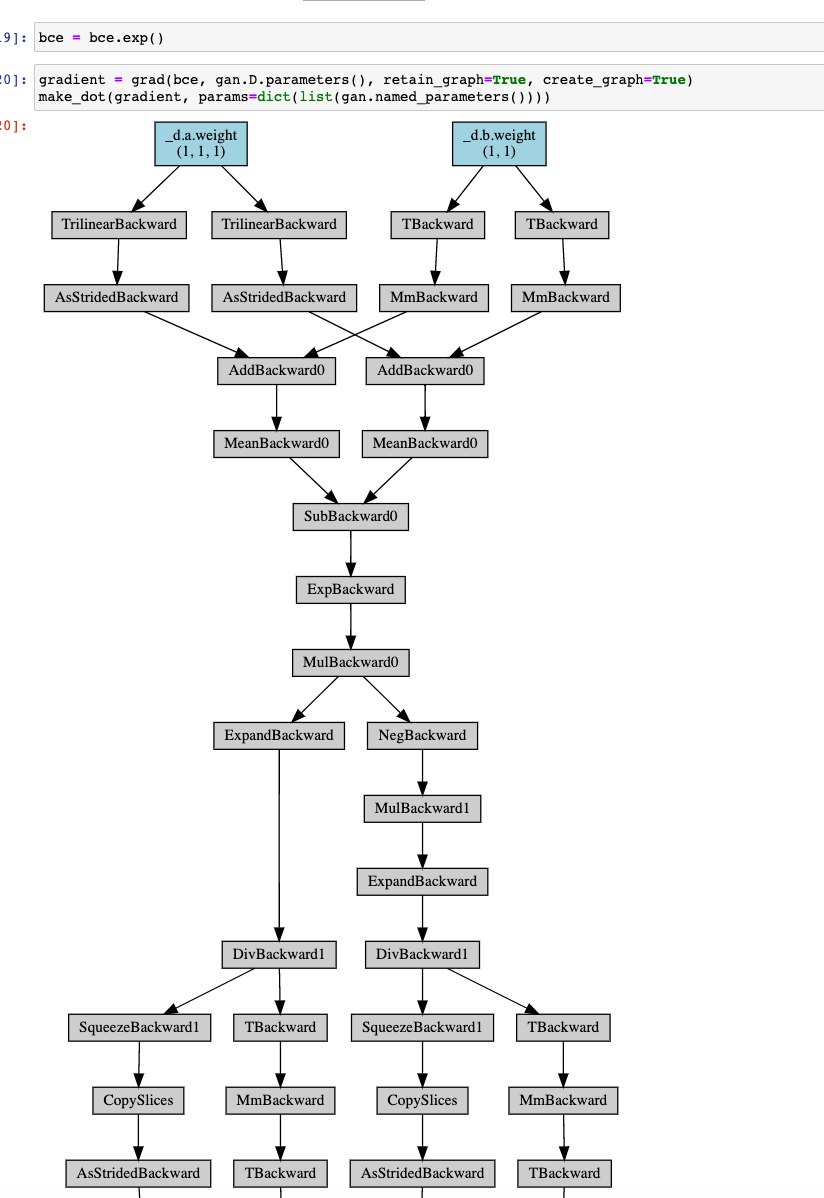
But when I try to differentiate it again I get no graph:

And here is the code for the discriminator. As you can see, I’m only using building blocks from torch.nn so requires_grad should be true for everything:
class Quadratic(nn.Module):
def __init__(self, in_features: int, out_features: int):
super(Quadratic, self).__init__()
self.a = nn.Bilinear(in_features, in_features, out_features, bias=False)
self.b = nn.Linear(in_features, out_features, bias=False)
def forward(self, x: Tensor) -> Tensor:
return self.a(x, x) + self.b(x)
I’ve been trying to debug this all day, any help would be greatly appreciated!