Hi ,
What I’m trying to do:
I’m trying to init weight in a bit weird way, I want the waits in network B (as seen below) will output a number around m (m is a real number), so I’m freezing the entire network, except B, and trying to do MSE (L2) loss, for few epochs, just to make B a bit closer to the number B.(It may be a stupid Idea, but let’s leave it aside for now)
It’s easier to understand like this:
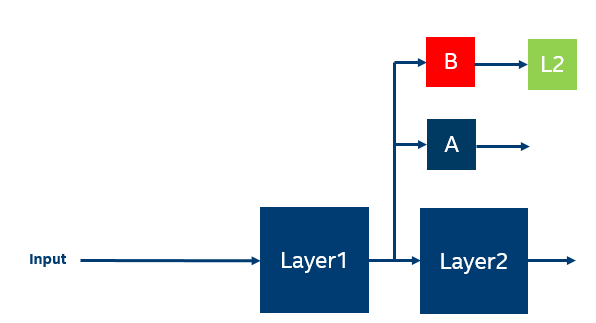
Now I’m trying to do the loss:
criterion= torch.nn.MSELoss()
loss = criterion(targets,dummy_threshold)
loss.backward()
And I’m getting the error in the title.
I believe that the backward movement starts from layer2 output and seeing requierd_grad=False, that’s the problem?
The big question How do I manage to train only the B network, while the other networks are frozen (require_grad =False).
(I can just extract B and then load the weights, but first I want to learn if there is any solution)
BTW, if my network has 3 outputs, where the backprop begins?
What do you think? I’ll be happy for your help.
Thanks!