I’m a PyTorch beginner and I’m trying to implement a recommender system based on the paper “Scalable Recommender Systems through Recursive Evidence Chains” ([1807.02150v1] Scalable Recommender Systems through Recursive Evidence Chains).
In this paper the latent factors Ui for users are defined in (3.1)
and the latent factors Vj for items are are defined in (3.2)
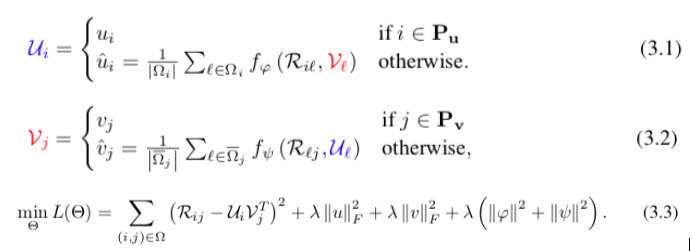
You can see that the definition of Ui depends on Vj, and vice-versa! Of course, there are cases where this recursion is infinite, and so the authors define a Max Depth constant after which it is forced to stop.
Here fφ and fψ both are 3-layer feed-forward neural network with each 200 neurons for each hidden layer.
My question is: with this kind of recursive definition, I have not been able to figure out how to code the training phase in which the goal is to minimize the loss function defined in (3.3).
The authors state: “While the definition of our latent feature vectors (U,V) rely on piece-wise functions, they are sub-differentiable and thus easy to optimize in a framework which supports automatic differentiation such as PyTorch or Tensorflow.” So it is possible!