I’m trying to simulate federated learning with a simple approach: I have a “local model” and some “workers” that have their own models (at the beginning just a copy from local model) and data. The data should be private so only the models can have access through ‘worker.model’
Every epoch after all workers are done with the training on own data a federated_aggregation function is called which calculates the average of all worker model parameters and save it to the specific local model parameter:
def federated_aggregation(local_model, workers):
with torch.no_grad():
for name, local_parameter in local_model.named_parameters():
parameter_stack = torch.zeros_like(local_parameter)
for worker in workers:
parameter_stack += worker.model.state_dict()[name].clone().detach()
parameter_stack /= len(workers)
local_parameter.set_(parameter_stack)
The thing is, when evaluating the local model, this doesn’t reflect the performance it should get after the training of the workers. A simple test to visualize this was to run a test with just one worker:
Performance of just one worker (training recall, validation recall) left, right the validation recall of local model:
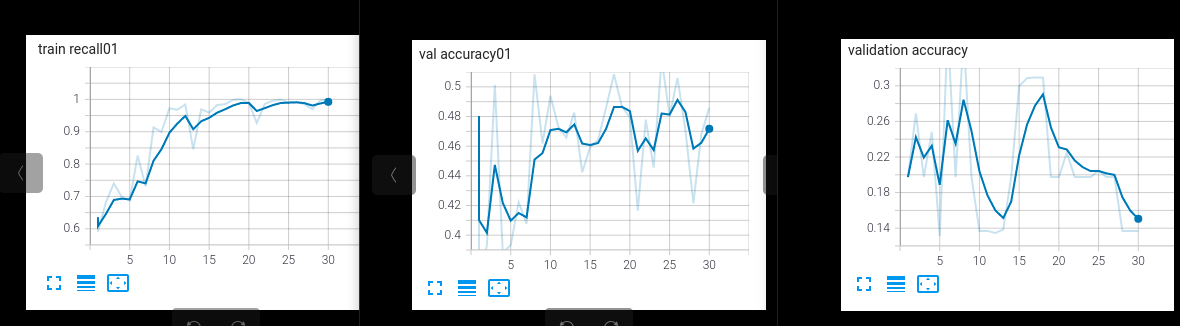
Any ideas what is the cause for this mismatch, I’ve tried different ways to update de local model parameter but I’m stuck in this behavior