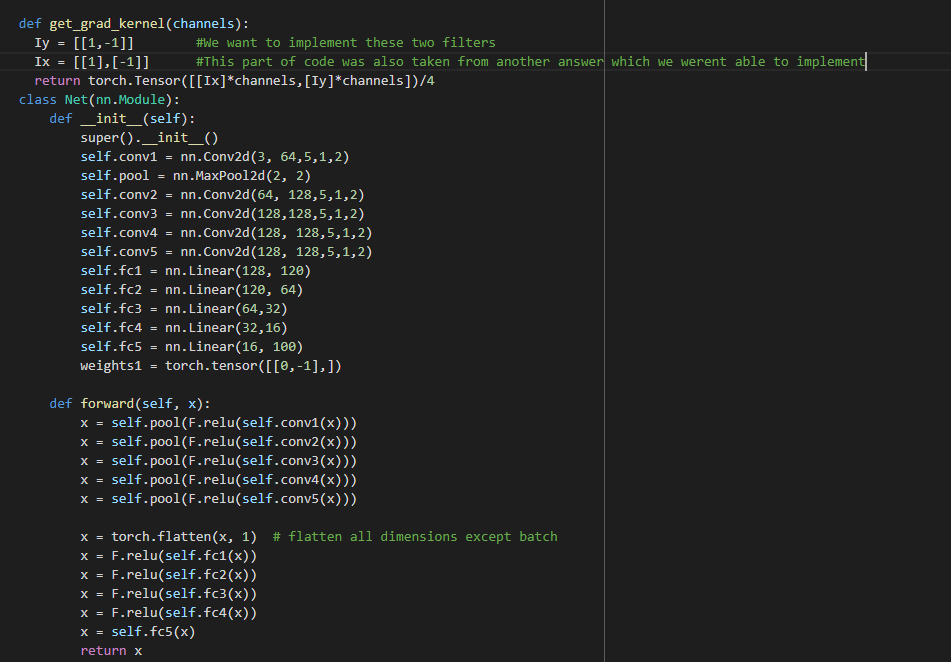
Hello in our project we are trying to implement several fixed filters
to each convolutional layer.
As shown in the code we have two filters that we want to add to each layer but weren’t able to grasp how we add these filters. If you could show us a way to do so we would be very grateful.
Forgot to add the code aswell
def get_grad_kernel(channels):
Iy = [[1,-1]] #We want to implement these two filters
Ix = [[1],[-1]] #This part of code was also taken from another answer which we werent able to implement
return torch.Tensor([[Ix]*channels,[Iy]*channels])/4
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64,5,1,2)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(64, 128,5,1,2)
self.conv3 = nn.Conv2d(128,128,5,1,2)
self.conv4 = nn.Conv2d(128, 128,5,1,2)
self.conv5 = nn.Conv2d(128, 128,5,1,2)
self.fc1 = nn.Linear(128, 120)
self.fc2 = nn.Linear(120, 64)
self.fc3 = nn.Linear(64,32)
self.fc4 = nn.Linear(32,16)
self.fc5 = nn.Linear(16, 100)
weights1 = torch.tensor([[0,-1],])
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = self.pool(F.relu(self.conv4(x)))
x = self.pool(F.relu(self.conv5(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = F.relu(self.fc4(x))
x = self.fc5(x)
return x
net = Net()
Assuming Iy and Ix should be used as filters in a conv layer you could assign them as the weight attribute as seen here.
From some of the similar questions i did find that solution but when I tried to make it into a fixed filter I got the following errors
Heres the code
batch_size = 10
channels = 3
h, w = 24, 24
x = torch.randn(batch_size, channels, h, w)
# View approach
conv = nn.Conv2d(1, 1, 2, 2, bias=False)
with torch.no_grad():
conv.weight = nn.Parameter(torch.tensor([[[[1, -1],
[-1, 1]]]]))
output = conv(x.view(-1, 1, h, w)).view(batch_size, channels, h//2, w//2)
Error: Only Tensors of floating point and complex dtype can require gradients
When I write the values between 0 and 1 it works just fine.
You are creating the weight tensor as a LongTensor, so either call .float() on it or use floating point values via:
with torch.no_grad():
conv.weight = nn.Parameter(torch.tensor([[[[1., -1.],
[-1., 1.]]]]))
1 Like
Thanks a lot for your help sire. This solved my issue which now I have to solve the issue of size but I’ll try fixing that on my own.