I’ve been trying to train an LSTM cell using a GPU, which works on a CPU, but get the following error.
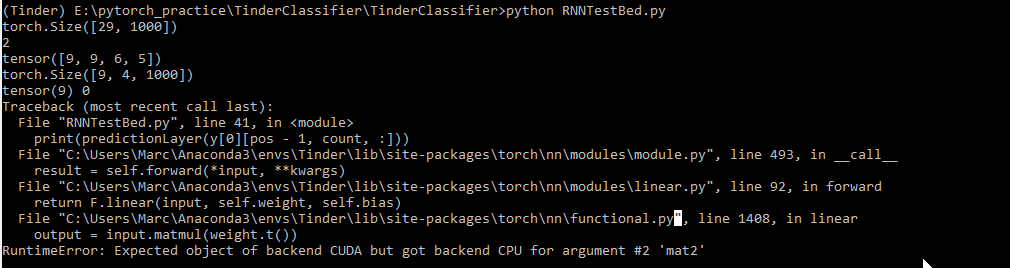
I’ve found this post (How to train LSTM with GPU - #17 by Crohn_eng), but have been using a custom collate function and haven’t found the answer to my issue in this post.
Below is the LSTM code:
import torch
import torch.nn.utils.rnn as rnn_utils
import torch.nn as nn
from torchUtils import SplitDataset
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def my_collate(batch):
# batch contains a list of tuples of structure (sequence, target)
data = [item[0] for item in batch]
data = rnn_utils.pack_sequence(data, enforce_sorted=False)
targets = [item[1] for item in batch]
return [data, targets]
dataset = SplitDataset(shuffleData=False) #ImageDataset()
dataset.selectPhase('train')
trainingDL = torch.utils.data.DataLoader(dataset, 4,shuffle=True, num_workers=0, collate_fn=my_collate)
inputs, labels = next(iter(trainingDL))
print(inputs[0].shape)
'''
a = torch.Tensor([[1, 2], [2, 3], [3, 4]])
b = torch.Tensor([[4, 5], [5, 6]])
c = torch.Tensor([[6, 7]])
packed = rnn_utils.pack_sequence([a, b, c])
'''
lstm = nn.LSTM(1000,1000, batch_first=True).to(device)
#device = torch.device("cpu")
packed_output, (h,c) = lstm(inputs.to(device))
y = rnn_utils.pad_packed_sequence(packed_output)
predictionLayer = nn.Linear(1000, 2)
print(len(y))
print(y[1])
print(y[0].shape)
currentIdx = -1
for count, pos in enumerate(y[1]):
print(pos, count)
print(predictionLayer(y[0][pos - 1, count, :]))
The custom dataset is the following:
class SplitDataset(MongoDataset):
def __init__(self, trainingProportion = 0.8, shuffleData = False):
MongoDataset.__init__(self)
trainingSetSize = int(len(self)*trainingProportion)
validSetSize = len(self) - trainingSetSize
# Could be replaced by something else rather than random replacement
random.shuffle(self.ids)
self.phase = 'train'
self.trainingSet = self.ids[0:trainingSetSize]
self.validationSet = self.ids[trainingSetSize:]
self.shuffleData = shuffleData
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.featureExtractor = models.vgg16(pretrained=True)
def __getitem__(self, i):
profile, label = MongoDataset.__getitem__(self,i)
# You could replace this with the online data loader
with torch.no_grad():
self.featureExtractor.eval()
preppedData = [self.featureExtractor(self.imageTransform(img).unsqueeze(0)).squeeze().to(self.device) for img in profile.images]
# TODO: Replace this a proper transform using Pytorch libs
if self.phase == 'train' and self.shuffleData:
np.random.shuffle(preppedData)
return torch.stack(preppedData), label
def selectPhase(self, phase):
self.phase = phase
if phase == 'val':
self.loadData = self.validationSet
self.transform = ProfileDataset.validationTransform
elif phase == 'train':
self.loadData = self.trainingSet
self.transform = ProfileDataset.trainingTransform
else:
raise("Invalid phase")
The error appears to be caused by the model’s weights, is it possible the model is only partially on the GPU?