Hi everyone
I am trying to add a pretrained BERT in Text classification example as a layer.
Firstly, the example set batch_size as 16, so I got the following error:
ValueError: Expected input batch_size(1) to match target batch_size(16)
Here is my code about model and train function
import torch.nn as nn
import torch.nn.functional as F
import numpy
class TextSentiment(nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super().__init__()
self.bert = BertModel.from_pretrained(model_name)
self.fc = nn.Linear(embed_dim, num_class)
def forward(self, text, offsets):
outputs = self.bert(text)
last_hidden_states = outputs[0]
print(last_hidden_states.shape)
return self.fc(last_hidden_states)
from sklearn.metrics import f1_score
from torch.utils.data import DataLoader
def train_func(sub_train_):
# Train the model
train_loss = 0
train_acc = 0
train_f1 = 0
data = DataLoader(sub_train_, batch_size=BATCH_SIZE, shuffle=True,
collate_fn=generate_batch)
for i, (text, offsets, cls) in enumerate(data):
optimizer.zero_grad()
offsets, cls = offsets.to(device), cls.to(device)
input_text = r"C:\pyproject\.data\ag_news_csv\train.csv"
text = berttokenizer.encode(input_text, add_special_tokens=True)
text = torch.LongTensor([text])
print(1, text.shape)
print(text)
output = model(text, offsets)
print(2, output.shape)
print(output)
loss = criterion(output, cls)
train_loss += loss.item()
loss.backward()
optimizer.step()
train_f1 += f1_score(cls, output.argmax(1), average='macro')
train_acc += (output.argmax(1) == cls).sum().item()
# Adjust the learning rate
scheduler.step()
return train_loss / len(sub_train_), train_acc / len(sub_train_), train_f1 / len(data)
and here is the result
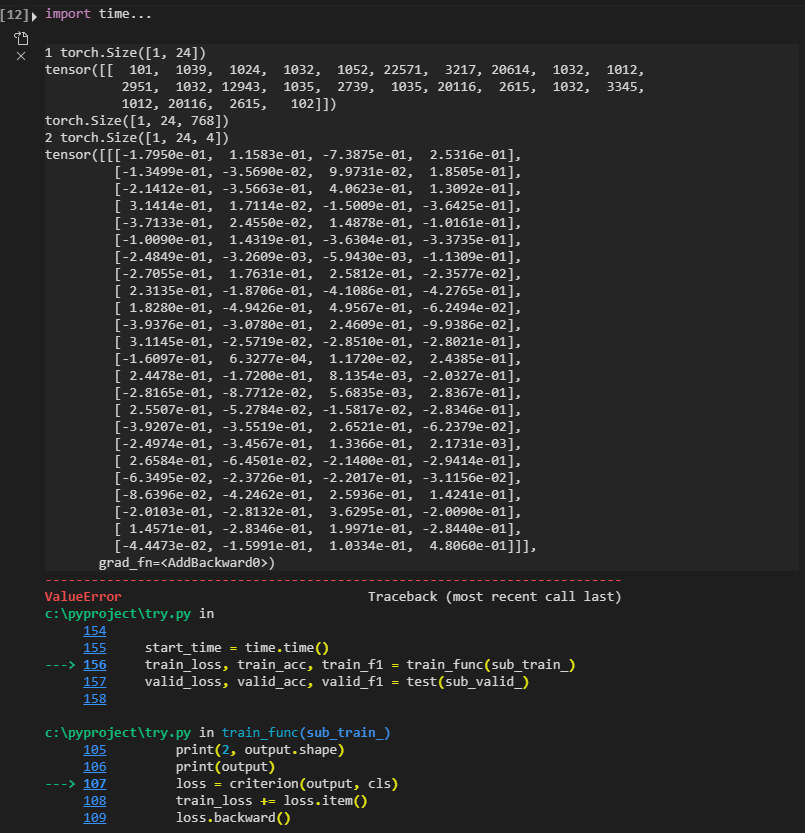
I do not know how to let input batch_size as 16, so I change the batch_size as 1, and I got another problem:
ValueError: Expected target size (1,4), got torch.Size([1])
Obviously, my problem is in the data shape but I can not fix it because I am new to pytorch or python.
Any help will be appreciated.