I have been trying to train a relatively simple two-tower net for recommendation. I am using PyTorch and the implementation is the following: basically embeddings layers for users and items, optional feed-forward net for both towers, dot product between the user and items representations, and sigmoid.
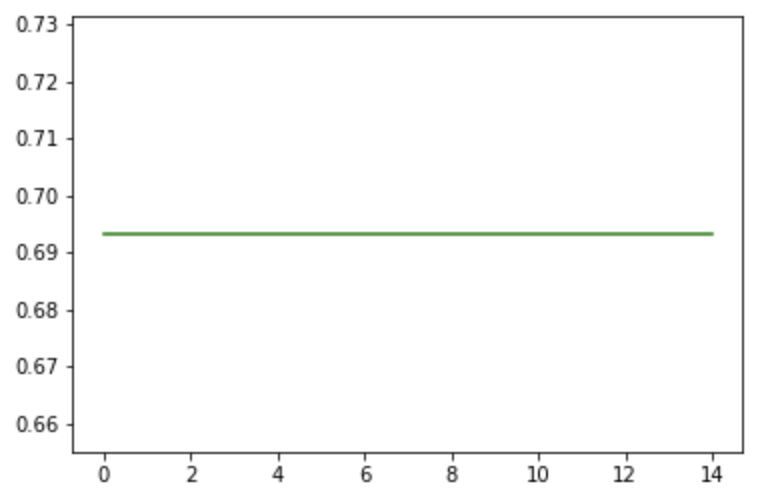
I am trining with Binary cross entropy loss and Adam optimizer. When I am using only the embeddings, I see improvements from epoch to epoch (loss is decreasing and the evaluation metric are increasing). However, once I add even a single feed-forward layer, the network learns just a bit in the first epoch and then stagnates. I have tried to had code one linear layer with ReLU, to check if the issue is with the way I am creating the list of layers, but this did not change anything.
Has anybody else had a similar problem?
Implementation:
class SimpleTwoTower(nn.Module):
def __init__(self, n_items, n_users, ln):
super(SimpleTwoTower, self).__init__()
self.ln = ln
self.item_emb = nn.Embedding(num_embeddings=n_items, embedding_dim=self.ln[0])
self.user_emb = nn.Embedding(num_embeddings=n_users, embedding_dim=self.ln[0])
self.item_layers = [] #nn.ModuleList()
self.user_layers = [] #nn.ModuleList()
for i, n in enumerate(ln[0:-1]):
m = int(ln[i+1])
self.item_layers.append(nn.Linear(n, m, bias=True))
self.item_layers.append(nn.ReLU())
self.user_layers.append(nn.Linear(n, m, bias=True))
self.user_layers.append(nn.ReLU())
self.item_layers = nn.Sequential(*self.item_layers)
self.user_layers = nn.Sequential(*self.user_layers)
self.dot = torch.matmul
self.sigmoid = nn.Sigmoid()
def forward(self, items, users):
item_emb = self.item_emb(items)
user_emb = self.user_emb(users)
item_emb = self.item_layers(item_emb)
user_emb = self.user_layers(user_emb)
dp = self.dot(user_emb, item_emb.t())
return self.sigmoid(dp)