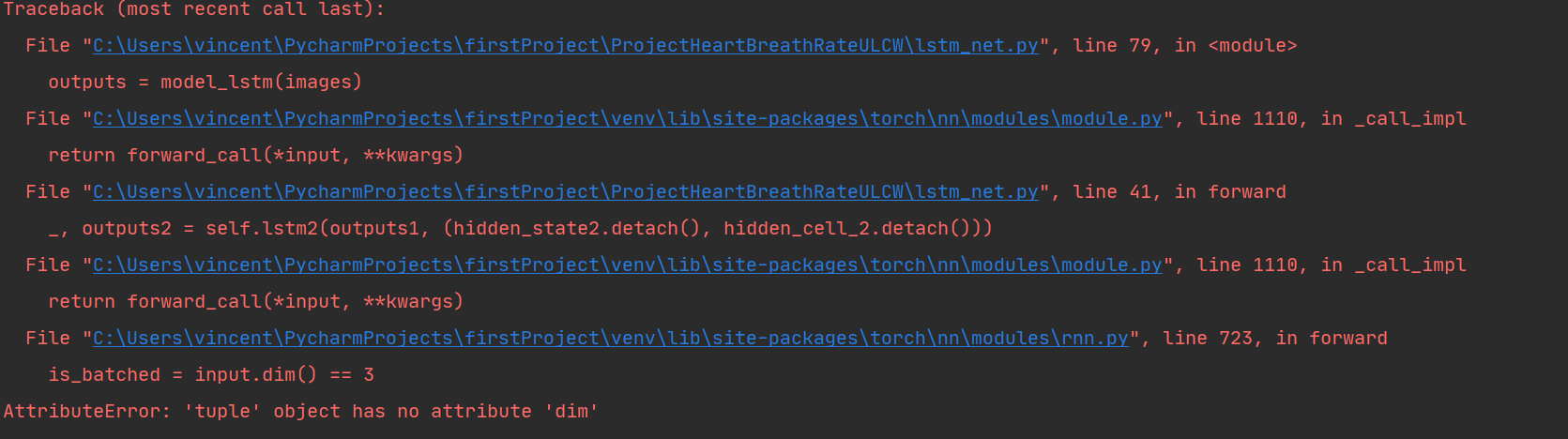
Hi, I am trying to compile CNN + LSTM for the imaging that first uses the CNN to train the network, then feeds to the LSTM while defining in sequence each time series of each predicted image.
Below is the code that generates the structure of my network. Indeed, the CNN network works well. Error is identified when I export the CNN module to LSTM. How to solve the error? I face two problems. The first one is located in this part of my script " images = images.view(-1, sequence_dim, INPUT_DIM).requires_grad()
TypeError: ‘bool’ object is not callable". The second displays this error “TypeError: ‘CNNLetNet’ object is not iterable”, when I remove the "view(-1, sequence_dim, INPUT_DIM).requires_grad()“. Need help, thanks.
class CNNLetNet(nn.Module):
def __init__(self):
super(CNNLetNet, self).__init__()
"""
@ defining four cnn network to perform our data
in a set of sequential layers
"""
self.conv1 = nn.Sequential(
nn.Conv2d(1, 6, 5, stride=1, padding=1)
)
self.conv2 = nn.Sequential(
nn.Conv2d(6, 16, 5, stride=1, padding=1)
)
self.conv3 = nn.Sequential(
nn.Conv2d(16, 32, 2, stride=1, padding=1)
)
self.fc1 = nn.Sequential(
nn.Linear(32 * 3 * 3, 120)
)
self.fc2 = nn.Sequential(
nn.Linear(120, 60)
)
self.fc3 = nn.Sequential(
nn.Linear(60, 10)
)
self.pool = nn.Sequential(
nn.MaxPool2d(2, 2)
)
import torch
import torch.nn as nn
from cnn_net import CNNLetNet, trainset, testset
from torch.utils.data import DataLoader
class LSTMNet(nn.Module):
"""
@ the primary goal is to design a sequential lstm network
with two layers to sequentially train the data
"""
def __init__(self, input_dim, hidden_dim1, hidden_dim2, layers_dim1, layers_dim2, output_dim):
super(LSTMNet, self).__init__()
# Hidden dimensions
self.hidden1 = hidden_dim1
self.hidden2 = hidden_dim2
# Number of hidden layers
self.layers_dim1 = layers_dim1
self.layers_dim2 = layers_dim2
self.cnns = CNNLetNet().to(device='cuda' if torch.cuda.is_available() else 'cpu')
# print(self.cnns)
self.lstm1 = nn.Sequential(
nn.LSTM(input_dim, hidden_dim1, layers_dim1, batch_first=True)
)
self.lstm2 = nn.Sequential(
nn.LSTM(hidden_dim1, hidden_dim2, layers_dim2, batch_first=True)
)
self.fc1 = nn.Sequential(
nn.Linear(hidden_dim2, output_dim)
)
def forward(self, x):
# Initialize hidden state with zeros
hidden_state1 = torch.zeros(self.layers_dim1, x.size(0), self.hidden1).requires_grad_()
# Initialize cell state
hidden_cell_1 = torch.zeros(self.layers_dim1, x.size(0), self.hidden1).requires_grad_()
hidden_state2 = torch.zeros(self.layers_dim2, x.size(0), self.hidden2).requires_grad_()
hidden_cell_2 = torch.zeros(self.layers_dim2, x.size(0), self.hidden2).requires_grad_()
cnn_outs = [] # creating an empty liste to affect CNN trained model
for conv in self.cnns:
cnn_outs.append(conv)
outs = torch.cat(cnn_outs)
outs = torch.flatten(outs, 1)
_, outputs1 = self.lstm1(outs, (hidden_state1, hidden_cell_1))
_, outputs2 = self.lstm2(outputs1, (hidden_state2, hidden_cell_2))
outputs = self.fc(outputs2[:, -1, :])
return outputs