TypeError: load_state_dict() takes from 2 to 3 positional arguments but 4 were given
The source code is as follows
def generate(self): self.net = DeepLab(num_classes=self.num_classes, backbone=self.backbone, downsample_factor=self.downsample_factor, pretrained=False)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.net.load_state_dict(torch.load(self.model_path, map_location=device), ['state_dict'], False)
self.net = self.net.eval()
print('{} model, and classes loaded.'.format(self.model_path))
if self.cuda:
self.net = nn.DataParallel(self.net)
self.net = self.net.cuda()
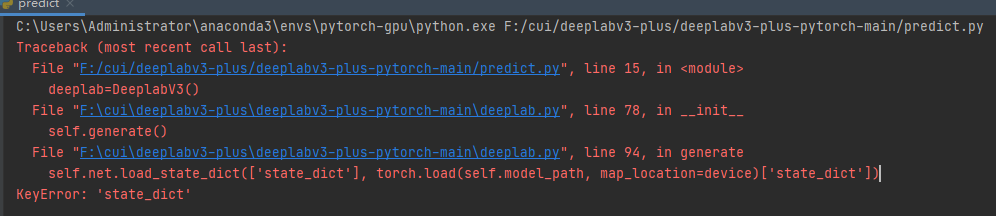
It seems the ['state_dict'] indexing is wrong and I guess you want to apply it on the loaded object?
If so, remove the , and use torch.load(self.model_path, map_location=device)['state_dict'].
I’m unsure why you’ve passed the ['state_dict'] list now as the path argument.
In any case, load_state_dict expects a state_dict as the first and strict as its second argument as described in the docs.
Check what kind of object you’ve saved previously, index it ,if needed, to get the state_dict of the loaded object, and pass it to load_state_dict().