Hello,
I am getting a TypeError: ‘Tensor’ object is not callable error in the batching stage of my program, I have seen in ither posts this can arise from treating a tensore as a function and atempting to call it. I am unsure where this is happening. I am knew to pytorch so any help is greatly appreciated.
The code below shows the full error message.
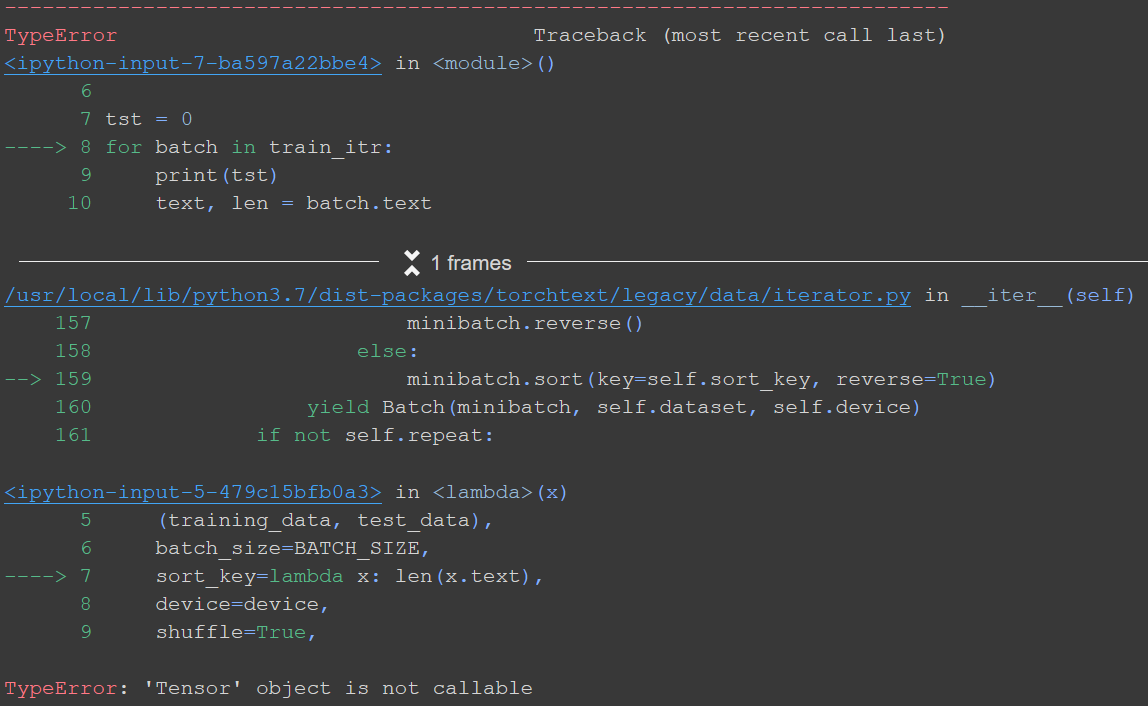
And below is shown the program leading up to the error.
tokenizer = get_tokenizer('spacy', language='en_core_web_sm')
TEXT = data.Field(tokenize=tokenizer, use_vocab=True, lower=True, batch_first=True, include_lengths=True)
LABEL = data.LabelField(dtype=torch.long, batch_first=True, sequential=False)
fields = {'TEXT': ('text', TEXT), 'CONCLUSION': ('label', LABEL)}
training_data = data.TabularDataset(
path='train.json',
format='json',
fields=fields,
skip_header=True,
)
test_data = data.TabularDataset(
path='test.json',
format='json',
fields=fields,
skip_header=True,
)
vectors = GloVe(name='6B', dim=200)
TEXT.build_vocab(training_data, vectors=vectors, max_size=10000, min_freq=1)
LABEL.build_vocab(training_data)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 2
train_itr, test_itr = BucketIterator.splits(
(training_data, test_data),
batch_size=BATCH_SIZE,
sort_key=lambda x: len(x.text),
device=device,
shuffle=True,
sort_within_batch=True,
sort=False
)
for batch_no, batch in enumerate(train_itr):
text, batch_len = batch.text
print(text, batch_len)
print(batch.label)
emb = nn.Embedding(2,4)# size of vocab = 2, vector len = 4
print(emb.weight)
model.embed.weight.data.copy_(TEXT.vocab.vectors)
print(model.embed.weight)
for batch in train_itr:
text, len = batch.text
emb = nn.Embedding(VOCAB_SIZE, EMBEDDING_DIM)
emb.weight.data.copy_(TEXT.vocab.vectors)
emb_out = emb(text)
pack_out = nn.utils.rnn.pack_padded_sequence(emb_out,
len,
batch_first=True)
rnn = nn.RNN(EMBEDDING_DIM, 4, batch_first=True)
out, hidden = rnn(pack_out)