hey, i’m using unet with pretrained resnet34 as encoder to segment diabetic retinopathy images, here is my full architectur
class Encoder(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(
resnet.conv1,
resnet.bn1,
nn.LeakyReLU(negative_slope=0.01),
resnet.layer1
)
self.layer2 = resnet.layer2
self.layer3 = resnet.layer3
self.layer4 = resnet.layer4
def forward(self, x):
x1 = self.layer1(x)
x2 = self.layer2(x1)
x3 = self.layer3(x2)
x4 = self.layer4(x3)
return x1, x2, x3, x4
and my middle conv is
class MiddleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=1)
self.relu1 = nn.LeakyReLU(negative_slope=0.01)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, stride=1)
self.relu2 = nn.LeakyReLU(negative_slope=0.01)
self.bn1 = nn.BatchNorm2d(out_channels)
def forward(self, inputs):
x = self.conv1(inputs)
x = self.relu1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.bn1(x)
return x
and my decoder and merge layer
class Dec_Block(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
# Up-Convolution
self.upconv = PixelShuffle_ICNR(in_channels, out_channels, scale = 2)
# LeakyReLU
self.relu = nn.LeakyReLU(negative_slope=0.01)
# Batch normalization
self.bn = nn.BatchNorm2d(out_channels, track_running_stats=False)
# Basic Block
self.conv = BasicBlock(in_channels+out_channels , out_channels)
def forward(self, inputs, skip):
up_x = self.upconv(inputs)
up_x = self.relu(up_x)
up_x = self.bn(up_x)
skip = nn.functional.interpolate(skip, size=up_x.size()[2:], mode='bilinear', align_corners=True)
x = torch.cat([up_x, skip], dim=1)
x = self.conv(x)
return x
class MergeLayer(nn.Module):
def __init__(self):
super(MergeLayer, self).__init__()
def forward(self, x, skip):
x = torch.cat([x, skip], dim=1)
return x
class Build_Unet(nn.Module):
def __init__(self):
super().__init__()
""" Encoder """
self.encoder = Encoder()
""" Middle Convolution """
self.mc1 = MiddleConv(512, 1024)
self.mc2 = MiddleConv(1024, 512)
""" Decoder """
self.decoder1 = Dec_Block(512, 256)
self.decoder2 = Dec_Block(256, 128)
self.decoder3 = Dec_Block(128, 64)
self.decoder4 = Dec_Block(64, 32)
""" Merge Layer """
self.merge = MergeLayer()
""" Segmentation Convolution """
self.segmentation = nn.Sequential(nn.Conv2d(35, 1, kernel_size=1))
def forward(self, x):
""" Encoder """
x1, x2, x3, x4 = self.encoder(x)
mc1 = self.mc1(x4)
mc2 = self.mc2(mc1)
""" Decoder """
d1 = self.decoder1(mc2, x4)
d2 = self.decoder2(d1, x3)
d3 = self.decoder3(d2, x2)
d4 = self.decoder4(d3, x1)
merged = self.merge(d4, x)
out = self.segmentation(merged)
return out
i train my model using batch size=2, learning rate=0.001, and epoch 30 with loss function BCE and Adam optimizer, but my dice coefficient getting low and my segmentation result look like this
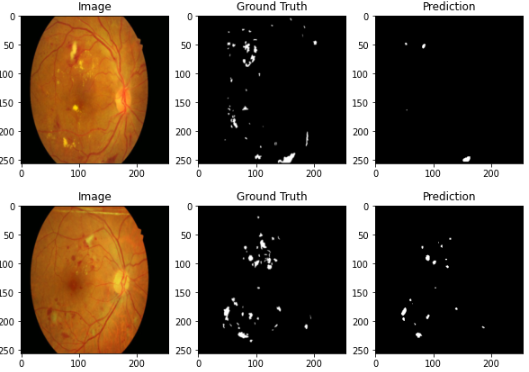
anyone knows how can i increase my model performance? thanks!