I am trying to train an ML model on time series data. The input is 10 timeseries which are essentially a sensor data. The output is another set of three time series. I feed the model with the window of 100. So, the input shape becomes (100, 10). I want to predict output time series values for single time step. So, the output shape becomes (1, 3). (If I create mini batches of size say x, the input and output shapes become (x, 100, 10) and (x, 1, 3)).
My approach is to first overfit the model on smaller number of records. See if model is indeed learning / able to overfit the data. Then add some regularization (mostly dropout) and then try to train the model on full dataset.
First, I tried to overfit LSTM model (4 LSTM layers with 1400 hidden units each) on small dataset and visualised the outcome. It did well. So, I tried to train it on the whole dataset. It did okayish, but still struggled at some places.
I tried adding dropouts too, but it did not yield any significant improvement. So, I tried to train PatchTST transformer model. First, I tried to overfit smaller model and did well. In fact, when I visualized the output, I realised that it was able to get tighter overfit than the LSTM model. So, I tried to train it on the whole dataset.
The initial version of PatchTST I tried is as follows:
config = PatchTSTConfig(
num_input_channels=10,
context_length=100,
num_targets=3,
patch_length=10,
patch_stride=10,
prediction_length=1,
num_hidden_layers=4,
num_attention_heads=8,
d_model=600,
)
model = PatchTSTForRegression(config)
# Model Trainer body looks like this:
patch_tst_y_hat = self.model(X)
y_hat = patch_tst_y_hat.regression_outputs
# for LSTM it was:
# y_hat = self.model(X)
loss = self.loss_fn(y_hat, Y)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
With this as base config, I tried different changes to it for hyper parameter optimization:
- layers = 7
- d_model = 1000
- d_model = 1000, num_attention_heads = 4
The validation loss curves as follows:
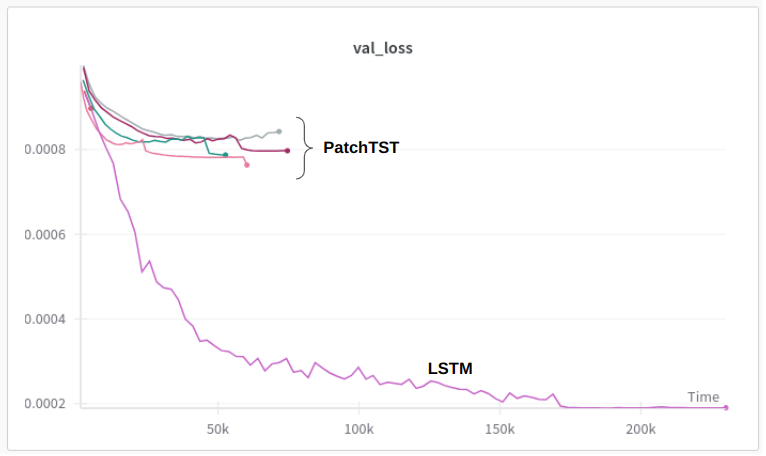
The training loss curves also look the same: image (Forum is allowing me to insert only one image)
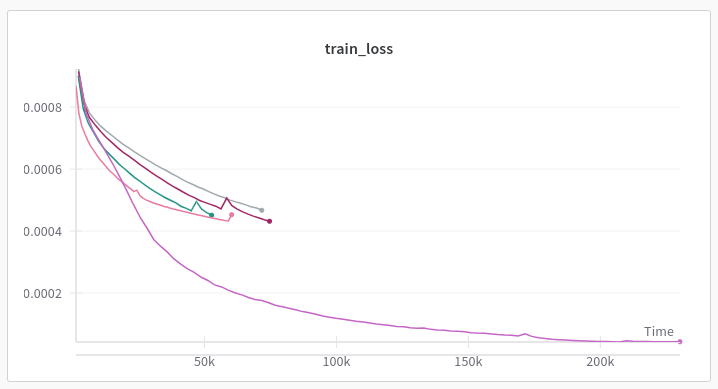{kind=link}
Can someone suggest any idea to improve LSTM model performance further with PatchTST or some other transformer related changes?
PS: I have also tried LSTM with attention, it did yield tiny improvement, which is not sufficient. I am also open for any non-transformer related suggestions too. But will love to learn how can we achieve better performance with transformer.