Hello,
I’m experiencing issues trying to execute my forward and backward propagation functions in parallel using PyTorch and CUDA streams. My code creates two different streams and attempts to execute the forward and backward propagation operations separately within these streams, but they do not seem to run in parallel.
Here is the relevant part of my code:
import torch
import numpy as np
from torch.cuda import nvtx
from contextlib import nullcontext
MB = 1 << 20
DTYPE = torch.FloatTensor
BS = 10000
REPEAT = 10
MBS = 1000
BUF_SHAPE = (256, 256)
print(f"BUF_SHAPE: {BUF_SHAPE}")
mm_parameter = torch.randn(BUF_SHAPE[0], BUF_SHAPE[0]).cuda()
def forward(input):
return input * mm_parameter
def backward(input):
return input * mm_parameter
def main():
test_stream = True
if test_stream:
stream1 = torch.cuda.Stream(priority=-1)
stream2 = torch.cuda.Stream(priority=0)
else:
stream1 = torch.cuda.default_stream()
stream2 = torch.cuda.default_stream()
PROFILE = True
data = torch.ones((BS, *BUF_SHAPE)).cuda()
print(f"Data size: {data.element_size() * data.nelement() / MB} MB")
input_list = torch.chunk(data, REPEAT, dim=0)
output_list = []
torch.cuda.synchronize()
forward_start_event = [torch.cuda.Event(enable_timing=True, blocking=True) for _ in range(REPEAT)]
forward_complete_event = [torch.cuda.Event(enable_timing=True, blocking=True) for _ in range(REPEAT)]
backward_start_event = [torch.cuda.Event(enable_timing=True, blocking=True) for _ in range(REPEAT)]
backward_complete_event = [torch.cuda.Event(enable_timing=True, blocking=True) for _ in range(REPEAT)]
def run(x_data):
output_list = []
for iteration in range(REPEAT):
with nvtx.range(f"iteration-{iteration}"):
with torch.cuda.stream(stream1):
with nvtx.range(f"forward-{iteration}"):
f_out = forward(x_data[iteration])
nvtx.mark(f"F-{iteration} done")
# print(f"output: {output.cpu().numpy()[0]}")
with torch.cuda.stream(stream2):
with nvtx.range(f"backward-{iteration}"):
output_list.append(backward(f_out))
nvtx.mark(f"B-{iteration} done")
torch.cuda.synchronize()
return output_list
import time
run(input_list)
run(input_list)
torch.cuda.synchronize()
start = time.time()
for epoch in range(10):
print(f"epoch: {epoch}")
with nvtx.range(f"Epoch_{epoch}"):
input_list = run(input_list)
torch.cuda.synchronize()
print("Finished")
print(f"time: {(time.time() - start)/10}")
torch.cuda.synchronize()
if __name__ == "__main__":
with torch.cuda.profiler.profile():
main()
Here is the relevant result of my nsys:

At the same time, I adjusted the priorities of the two streams to be the same, but I still couldn’t achieve pipelined parallelism between the forward and backward operations.
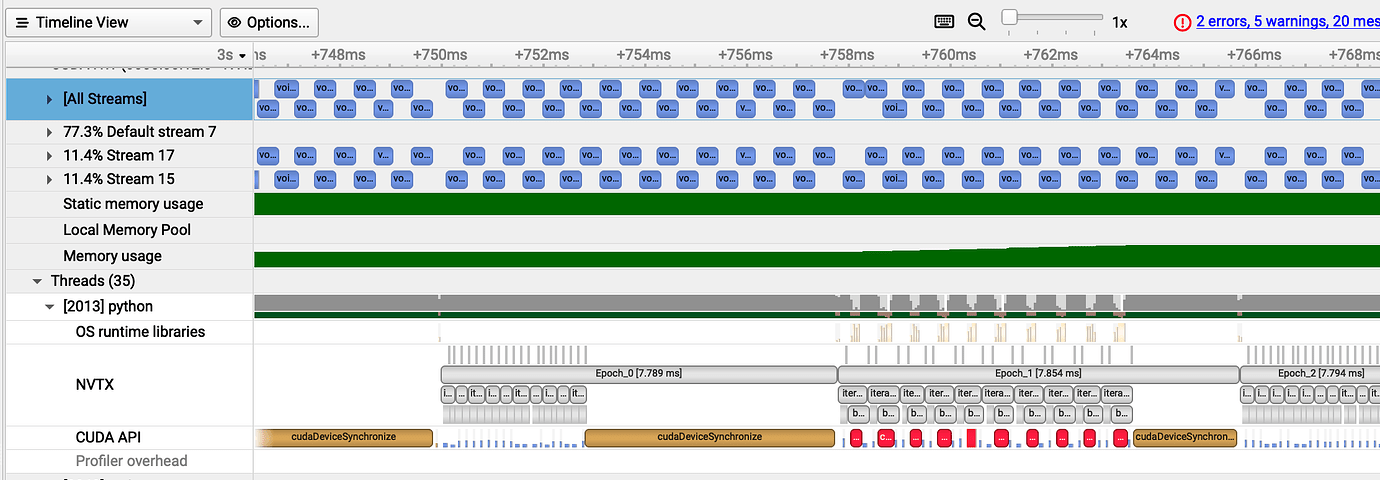
I have verified that both functions do not run simultaneously before calling torch.cuda.synchronize(). I expected these operations to run in parallel in different streams, but they appear to be executed sequentially. What could be the reason for this? Are there any suggested solutions?