Hello! I have tried every possible solution to this problem on my own, but I cannot for the life of me get this to work, so I turn to here to see if anyone can see what I am missing.
I will try to be brief. I built a convolutional neural network to try to learn vertex coordinates: (r, theta, phi) from a set of voltage values: [24,1024,3] matrix of voltages that range from 0 to 1 V.
It should be noted that this matrix is 93% consisting of zeroes, so it is very sparse, and the voltage data is “bunched” up in groups. In other words, voltage is not “sprinkled” in my matrix, rather the non-zero voltage values are typically close together, but it is the relative position of these clumps that is important for my task.
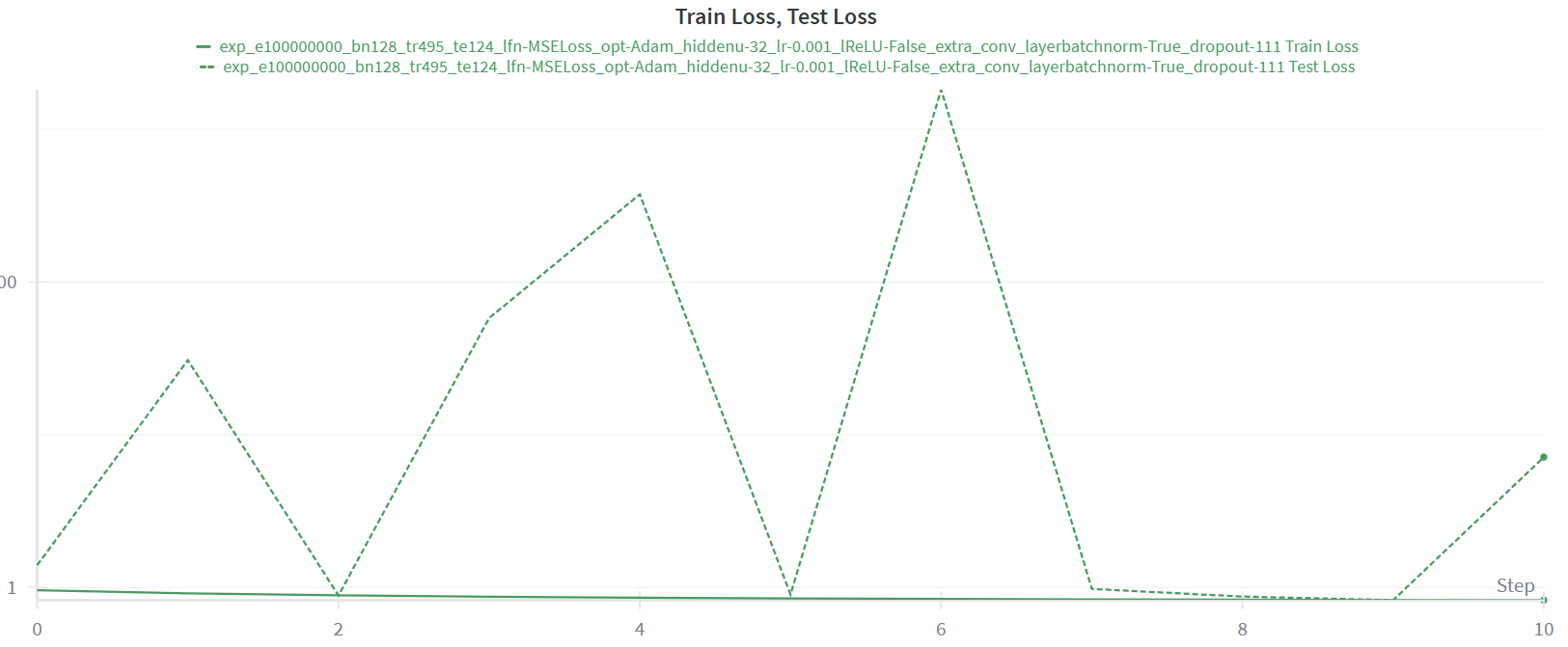
Anyways, I have been trying to use batch normalization to speed up the training process but it seems to blow up my test loss. Below is an example, where my train loss decreases nicely, but my test loss explodes all over the place (this is a log scale!).
Here is a torch.summary of my architecture:
=========================================================================================================
Layer (type:depth-idx) Output Shape Param #
=========================================================================================================
RNO_four_1_1_1s_batch_norm_dropout_extraconv_nonleak [128, 3] --
├─Sequential: 1-1 [128, 10, 21, 1023, 4] --
│ └─BatchNorm3d: 2-1 [128, 1, 24, 1024, 4] 2
│ └─Dropout3d: 2-2 [128, 1, 24, 1024, 4] --
│ └─Conv3d: 2-3 [128, 10, 23, 1025, 4] 90
│ └─BatchNorm3d: 2-4 [128, 10, 23, 1025, 4] 20
│ └─Dropout3d: 2-5 [128, 10, 23, 1025, 4] --
│ └─ReLU: 2-6 [128, 10, 23, 1025, 4] --
│ └─Conv3d: 2-7 [128, 10, 22, 1024, 4] 810
│ └─BatchNorm3d: 2-8 [128, 10, 22, 1024, 4] 20
│ └─Dropout3d: 2-9 [128, 10, 22, 1024, 4] --
│ └─ReLU: 2-10 [128, 10, 22, 1024, 4] --
│ └─Conv3d: 2-11 [128, 10, 21, 1023, 4] 810
│ └─BatchNorm3d: 2-12 [128, 10, 21, 1023, 4] 20
│ └─ReLU: 2-13 [128, 10, 21, 1023, 4] --
├─Sequential: 1-2 [128, 10, 10, 255, 1] --
│ └─Conv3d: 2-14 [128, 10, 20, 1020, 3] 1,610
│ └─BatchNorm3d: 2-15 [128, 10, 20, 1020, 3] 20
│ └─ReLU: 2-16 [128, 10, 20, 1020, 3] --
│ └─MaxPool3d: 2-17 [128, 10, 10, 255, 1] --
│ └─BatchNorm3d: 2-18 [128, 10, 10, 255, 1] 20
├─Sequential: 1-3 [128, 3, 9, 31, 1] --
...
Input size (MB): 50.33
Forward/backward pass size (MB): 6930.51
Params size (MB): 0.02
Estimated Total Size (MB): 6980.86
=========================================================================================================
And below are my train/test functions:
import logging
import torch
def train_step(model: torch.nn.Module, data_loader: torch.utils.data.DataLoader, loss_fn: torch.nn.Module, optimizer: torch.optim, device: torch.device, logger: logging.Logger):
"""
Performs one training epoch over the entire batched dataset.
Args:
model: PyTorch neural network model to train
dataloader: DataLoader containing training batches
loss_fn: Loss function (e.g., CrossEntropyLoss, MSELoss)
optimizer: Optimization algorithm (e.g., Adam, SGD)
device: Device to run computations on (CPU/CUDA)
logging: Logger for logging training progress
Returns:
float: Average training loss across all batches in the epoch
"""
# Set model to training mode - enables dropout, batch normalization training behavior
model.train()
# Initialize list to store loss from each batch
batch_train_losses = []
# Loop through all batches
for batch, (X, y) in enumerate(data_loader):
# Move input features and labels to the specified device
X, y = X.to(device), y.to(device)
# Forward pass
y_pred = model(X)
# Squeeze labels. Only matters if batch size = 1. Will convert y from y.shape = [1,3] to [3]
y = y.squeeze()
if logger.isEnabledFor(logging.DEBUG):
logger.debug(f'Batch {batch}:')
logger.debug([(yp, y0) for yp, y0 in zip(y_pred[0], y[0])])
# Calculate loss
loss = loss_fn(y_pred, y)
batch_train_losses.append(loss.item())
# Backward pass
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0)
optimizer.step()
# for name, param in model.named_parameters(): For debugging
# if param.grad is not None:
# print(f"{name} - grad norm: {param.grad.norm().item()}")
# else:
# print(f"{name} - NO GRADIENT")
# Return the average loss across all batches in this training epoch
return sum(batch_train_losses) / len(batch_train_losses)
import logging
import torch
def test_step(model: torch.nn.Module, data_loader: torch.utils.data.DataLoader, loss_fn: torch.nn.Module, device: torch.device, logger: logging.Logger):
"""
Performs one testing epoch over the entire batched dataset.
Args:
model: PyTorch neural network model to train
dataloader: DataLoader containing training batches
optimizer: Optimization algorithm (e.g., Adam, SGD)
device: Device to run computations on (CPU/CUDA)
logging: Logger for logging testing progress
Returns:
float: Average training loss across all batches in the epoch
"""
# Set model to evaluation mode - disables dropout, batch normalization training behavior
model.eval()
# Initialize list to store loss from each batch
batch_test_losses = []
# Stop tracking gradients and loop through all batches
with torch.inference_mode():
for batch, (X, y) in enumerate(data_loader):
# Move input features and labels to the specified device
X, y = X.to(device), y.to(device)
# Forward pass
y_pred = model(X)
# Squeeze labels. Only matters if batch size = 1. Will convert y from y.shape = [1,3] to [3]
y = y.squeeze()
if logger.isEnabledFor(logging.DEBUG):
logger.debug(f'Batch {batch}:')
logger.debug([(yp, y0) for yp, y0 in zip(y_pred[0], y[0])])
# Calculate loss
loss = loss_fn(y_pred, y)
batch_test_losses.append(loss.item())
# Return the average loss across all batches in this testing epoch
return sum(batch_test_losses) / len(batch_test_losses)
I am calling these with 128 batch size and MSELoss function.
Thank you very much! Any sort of advise (even if unrelated to the question) is appreciated! And please let me know if I am missing any crucial evidence.