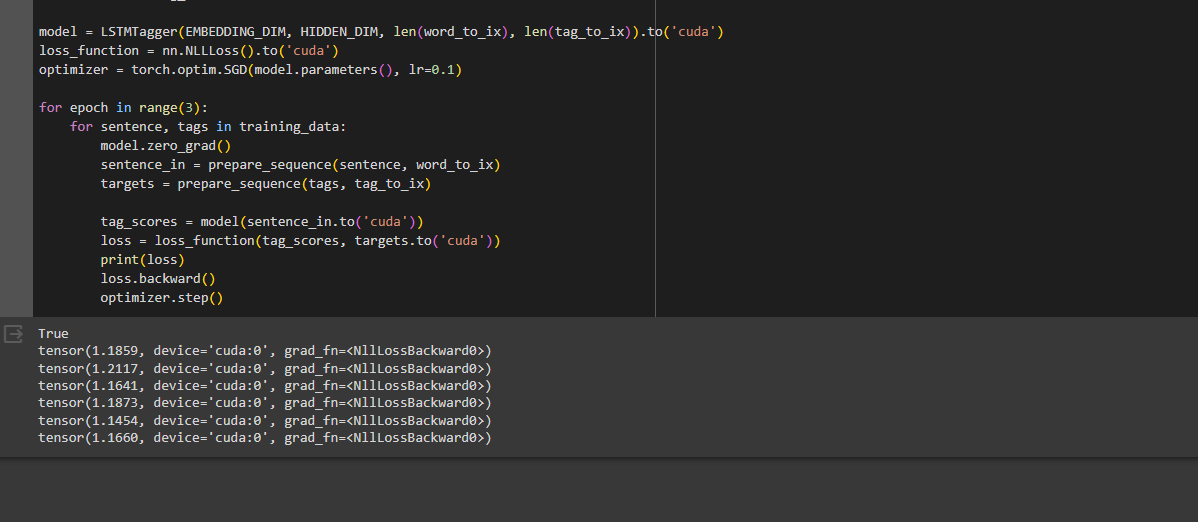
This is my code to set the seed values right after the imports:
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
torch.use_deterministic_algorithms(True)
os.environ['PYTHONHASHSEED'] = str(seed)
But I can’t achieve reproducible result. For example:
import os
import pandas as pd
import numpy as np
import sys
import torch
import torch.nn as nn
import random
import torch.nn.functional as F
import torch.optim as optim
print(torch.cuda.is_available())
os.environ["CUDA_VISIBLE_DEVICES"] = '1'
os.environ['CUBLAS_WORKSPACE_CONFIG']=':4096:8'
pd.set_option('display.max_columns', None)
# добавим корневую папку, в ней лежат все необходимые полезные функции для обработки данных
sys.path.append('./../../')
sys.path.append('./../')
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
torch.use_deterministic_algorithms(True)
os.environ['PYTHONHASHSEED'] = str(seed)
seed_everything(7)
def prepare_sequence(seq, to_ix):
idxs = [to_ix[w] for w in seq]
return torch.tensor(idxs, dtype=torch.long)
training_data = [
("The dog ate the apple".split(), ["DET", "NN", "V", "DET", "NN"]),
("Everybody read that book".split(), ["NN", "V", "DET", "NN"])
]
word_to_ix = {}
for sent, tags in training_data:
for word in sent:
if word not in word_to_ix: # word has not been assigned an index yet
word_to_ix[word] = len(word_to_ix) # Assign each word with a unique index
tag_to_ix = {"DET": 0, "NN": 1, "V": 2} # Assign each tag with a unique index
EMBEDDING_DIM = 6
HIDDEN_DIM = 6
class LSTMTagger(nn.Module):
def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size):
super(LSTMTagger, self).__init__()
self.hidden_dim = hidden_dim
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim)
self.hidden2tag = nn.Linear(hidden_dim, tagset_size)
def forward(self, sentence):
embeds = self.word_embeddings(sentence)
lstm_out, _ = self.lstm(embeds.view(len(sentence), 1, -1))
tag_space = self.hidden2tag(lstm_out.view(len(sentence), -1))
tag_scores = F.log_softmax(tag_space, dim=1)
return tag_scores
model = LSTMTagger(EMBEDDING_DIM, HIDDEN_DIM, len(word_to_ix), len(tag_to_ix)).to('cuda')
loss_function = nn.NLLLoss().to('cuda')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(10):
for sentence, tags in training_data:
model.zero_grad()
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = prepare_sequence(tags, tag_to_ix)
tag_scores = model(sentence_in.to('cuda'))
loss = loss_function(tag_scores, targets.to('cuda'))
print(loss)
loss.backward()
optimizer.step()

But but for the next training of the same model:
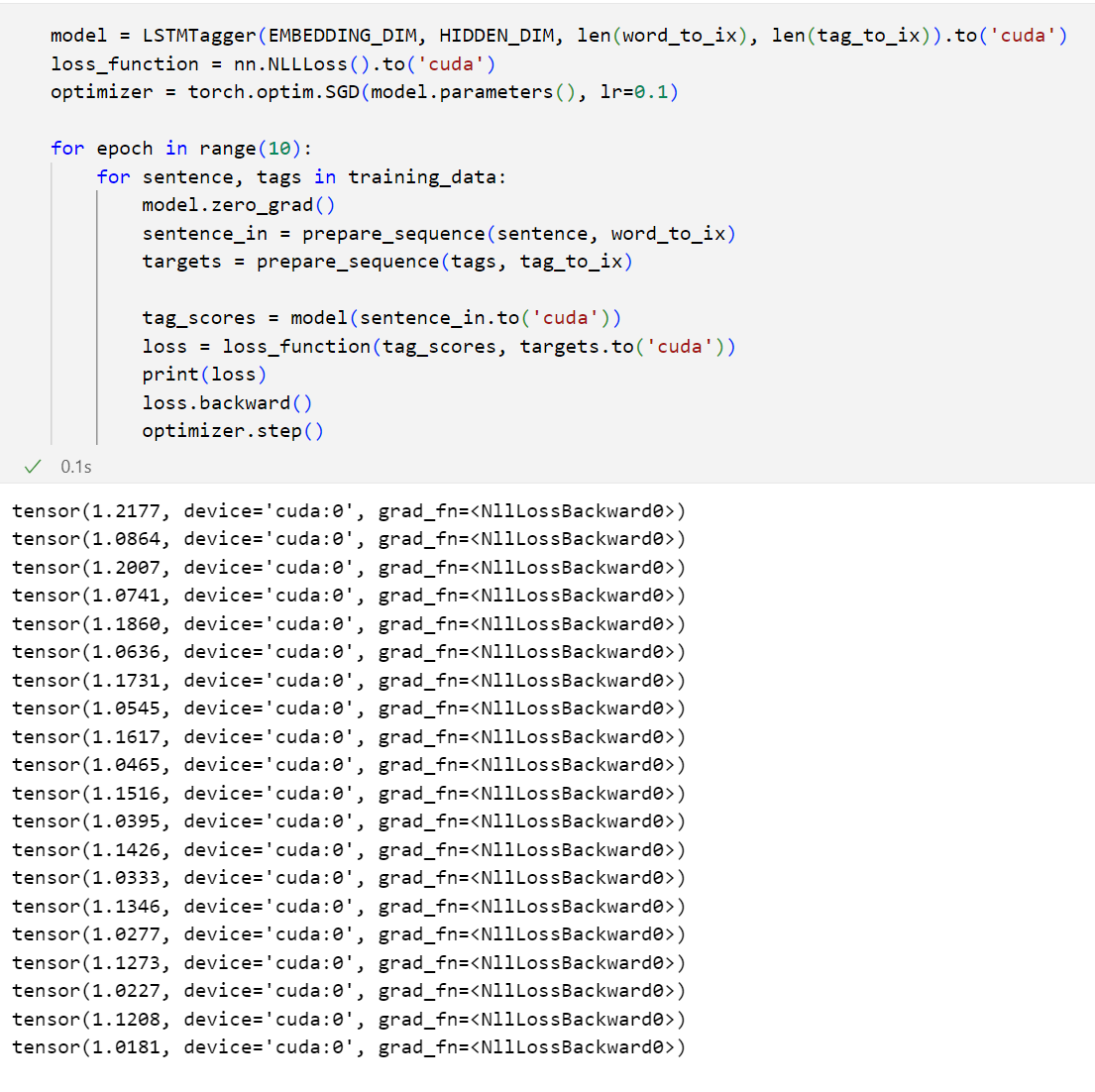
That is, losses are not reproduced with the same seed