I am not able to figure out the reason for jump in training loss that I get, after loading from the saved checkpoint. I am using Adam optimizer.
Model base - Load pretrained vgg16 model weights
def base_model_vgg16(num_freeze_top):
vgg16 = models.vgg16(pretrained=True)
vgg_feature_extracter = vgg16.features[:-1]
# Freeze learning of top few conv layers
for layer in vgg_feature_extracter[:num_freeze_top]:
for param in layer.parameters():
param.requires_grad = False
return vgg_feature_extracter.to(device)
Actual Model - create new model
class YOLONetwork(nn.Module):
def __init__(self, extractor):
super().__init__()
self.extractor = extractor
self.conv1 = nn.Conv2d(512, 1024,3,1,1)
self.pool1 = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(1024, 1024,3,1,1)
self.pool2 = nn.MaxPool2d(2,2)
self.lin1 = nn.Flatten()
self.drop1 = nn.Dropout(p=0.5)
self.lin2 = nn.Linear(7*7*1024, 7*7*(num_classes + anchors_per_box*5))
def forward(self,x):
out = self.extractor(x)
out = self.pool1(F.relu(self.conv1(out)))
out = self.pool2(F.relu(self.conv2(out)))
out = self.drop1(F.relu(self.lin1(out)))
out = torch.sigmoid(self.lin2(out))
num = out.shape[0]
return out.contiguous().view(num,7,7,-1)
Creating new model and optimiser
extractor = base_model_vgg16(10)
net = YOLONetwork(extractor).to(device)
loss_hist = []
valid_hist = []
best_valid_loss = 100000
optimizer = optim.Adam(net.parameters(), lr=0.00001)
epoch_start = 0
Saving model
PATH = 'drive/My Drive/saved_models/current.pt'
torch.save({
'net_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss_hist':loss_hist,
'valid_hist':valid_hist,
'best_valid_loss':best_valid_loss,
'epoch_start':epoch
}, PATH)
Loading Model :
checkpoint = torch.load(load_model, map_location=device)
net.load_state_dict(checkpoint['net_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
loss_hist = checkpoint['loss_hist']
valid_hist = checkpoint['valid_hist']
best_valid_loss = checkpoint['best_valid_loss']
epoch_start =checkpoint['epoch_start']
net.train()
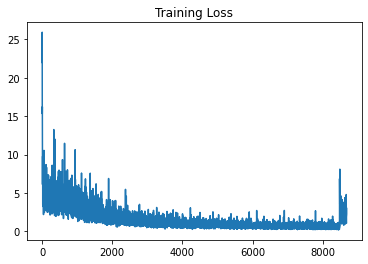
I am unable to figure out the reason for the training loss jump once the training is resumed from a checkpoint.
Thank you very much ![]()