Hello, I am working on a demo semantic segmentation project using SegFormer, I am implementing the code from scratch using the original codebase by tweaking the parameters.
I am not able to train the model properly, when I logged the model to tensorboard, I noticed not all transformer blocks were appearing and also there were many breaks in the computation graph
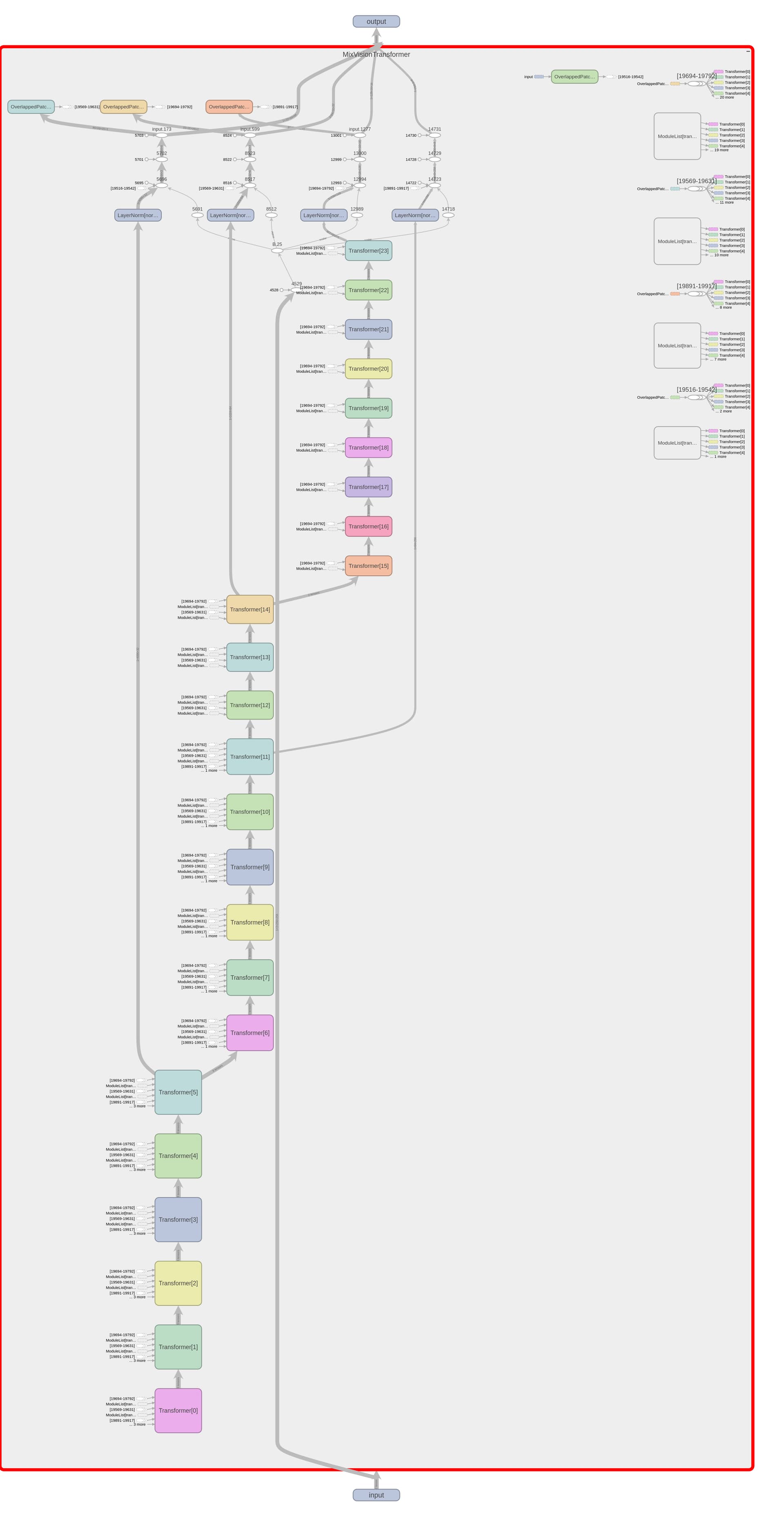
class MixVisionTransformer(nn.Module):
"""
### MixVisionTransformer
Args:
in_channels (int): input dimension, defaults to 3
num_classes (int): number of classes, defaults to 1000
depths (list): depth of each stage, defaults to [3, 4, 6, 3]
embed_dims (list): embedding dimension of each stage, defaults to [64, 128, 256, 512]
num_heads (list): number of attention heads of each stage, defaults to [1, 2, 4, 8]
mlp_ratio (float): ratio of mlp hidden dim to embedding dim, defaults to 4.0
qkv_bias (bool): if True, add a learnable bias to query, key, value, defaults to True
qk_scale (float): override default qk scale of head_dim ** -0.5 if set, defaults to None
drop_rate (float): dropout rate, defaults to 0.
attn_drop_rate (float): attention dropout rate, defaults to 0.
drop_path_rate (float): stochastic depth rate
Returns:
torch.Tensor: list of output tensor
"""
def __init__(self, in_channel:int=3, image_size:int=256, patch_size:int=4, num_classes:int=512, embed_dims:list=[64, 128, 256, 512],
num_heads:list=[1, 2, 4, 8], mlp_ratio:float=4., qkv_bias:bool=False, qk_scale:float=0.,
drop_rate:float=0., attn_drop_rate:float=0., drop_path_rate:float=0.1, norm_layer:nn.Module=nn.LayerNorm,
depths:list=[3, 4, 6, 3], sr_ratios:list=[8, 4, 2, 1]) -> None:
super(MixVisionTransformer, self).__init__()
self.projection_dim = num_classes
self.image_size = image_size
self.embed_dims = embed_dims
self.num_heads = num_heads
self.patch_embed1 = OverlappedPatchEmbedding(patch_size=7, in_channels=in_channel, stride=4, embed_dim=self.embed_dims[0])
self.patch_embed2 = OverlappedPatchEmbedding(patch_size=3, in_channels=self.embed_dims[0], stride=2, embed_dim=self.embed_dims[1])
self.patch_embed3 = OverlappedPatchEmbedding(patch_size=3, in_channels=self.embed_dims[1], stride=2, embed_dim=self.embed_dims[2])
self.patch_embed4 = OverlappedPatchEmbedding(patch_size=3, in_channels=self.embed_dims[2], stride=2, embed_dim=self.embed_dims[3])
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
self.transformerblock1 = nn.ModuleList([
Transformer(in_channels=self.embed_dims[0], num_heads=self.num_heads[0], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur+i], norm_layer=nn.LayerNorm, sr_ratio=sr_ratios[0], view_attention=True)
for i in range(depths[0])
])
self.norm1 = norm_layer(self.embed_dims[0])
cur += depths[0]
self.transformerblock2 = nn.ModuleList([
Transformer(in_channels=self.embed_dims[1], num_heads=self.num_heads[1], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur+i], norm_layer=nn.LayerNorm, sr_ratio=sr_ratios[1], view_attention=True)
for i in range(depths[1])
])
self.norm2 = norm_layer(self.embed_dims[1])
cur += depths[1]
self.transformerblock3 = nn.ModuleList([
Transformer(in_channels=self.embed_dims[2], num_heads=self.num_heads[2], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur+i], norm_layer=nn.LayerNorm, sr_ratio=sr_ratios[2], view_attention=True)
for i in range(depths[2])
])
self.norm3 = norm_layer(self.embed_dims[2])
cur += depths[2]
self.transformerblock4 = nn.ModuleList([
Transformer(in_channels=self.embed_dims[3], num_heads=self.num_heads[3], mlp_ratio=mlp_ratio, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur+i], norm_layer=nn.LayerNorm, sr_ratio=sr_ratios[3], view_attention=True)
for i in range(depths[3])
])
self.norm4 = norm_layer(self.embed_dims[3])
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x:torch.Tensor) -> list:
"""
Forward pass of the MixVisionTransformer
Args:
x (torch.Tensor): input tensor, shape (B, C, H, W)
Returns:
out (list): list of different spatial tensors.
"""
B = x.shape[0]
outs = []
x, H, W = self.patch_embed1(x)
for i, blk in enumerate(self.transformerblock1):
x = blk(x, H, W)
x = self.norm1(x).reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
x, H, W = self.patch_embed2(x)
for i, blk in enumerate(self.transformerblock2):
x = blk(x, H, W)
x = self.norm2(x).reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
x, H, W = self.patch_embed3(x)
for i, blk in enumerate(self.transformerblock3):
x = blk(x, H, W)
x = self.norm3(x).reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
x, H, W = self.patch_embed4(x)
for i, blk in enumerate(self.transformerblock4):
x = blk(x, H, W)
x = self.norm4(x).reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
return outs
This is the code for the transformer encoder.