Hello Everyone,
I’m hesitant posting this here as I’m not sure if this forum is open to debugging questions. Nevertheless, I’m willing to take my chances.
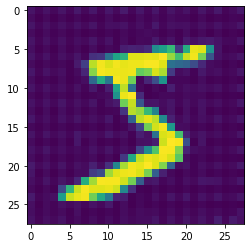
I have followed this tutorial right here to build my own VAE, which I train on my custom data set with the same type of images as MNIST which is used on the tutorial(28x28, black and white).
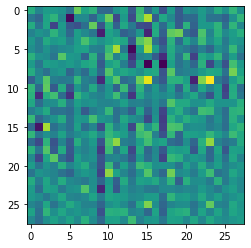
However, I must have done something wrong while implementing it, since my model won’t learn anything. It just outputs a specific pattern for each input image ,as you can see below, even though the input images have huge differences.

This problem persists and the model insists even more so on this random pattern and just disregards the input.
I’ve included my code below. I can say that I have verified a couple things about my implementation after seeing people having similar issues. I’m pretty sure all my gradients are updating. I also checked to see where this pattern is coming from and it seems like the encoder part is doing its job really well i.e. it outputs different encodings for different images. For some reason, the decoder just interprets these different encodings to very similar output images.
Any kind of suggestion would be much appreciated, and I am ready to supply any kind of debugging information you might request. Thank you in advance
Encoder
class VariationalEncoder(nn.Module):
def __init__(self, latent_dimensions):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(1, 8, 3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(8, 16, 3, stride=2, padding=1),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.Conv2d(16,32,3, stride=2, padding=0),
nn.ReLU(),
nn.Flatten(start_dim=1),
nn.Linear(3 * 3 * 32, 128),
nn.ReLU(),
)
self.linear1 = nn.Linear(128, latent_dimensions)
self.linear2 = nn.Linear(128, latent_dimensions)
self.N = torch.distributions.Normal(0, 1)
self.KLDivergence = 0
def forward(self, x):
out = self.model(x)
mean = self.linear1(out)
stddev = torch.exp(self.linear2(out))
# mu = self.linear2(x)
# sigma = torch.exp(self.linear3(x))
# z = mu + sigma*self.N.sample(mu.shape)
# self.kl = (sigma**2 + mu**2 - torch.log(sigma) - 1/2).sum()
z = mean + stddev * self.N.sample(stddev.shape)
self.KLDivergence = (stddev**2 + mean**2 - torch.log(stddev) - 1/2).sum()
return z
Decoder
class Decoder(nn.Module):
def __init__(self, latent_dimensions):
super().__init__()
self.decoder_lin = nn.Sequential(
nn.Linear(latent_dimensions, 128),
nn.ReLU(True),
nn.Linear(128, 3 * 3 * 32),
nn.ReLU(True),
)
self.unflatten = nn.Unflatten(dim=1, unflattened_size=(32, 3, 3))
self.decoder_conv = nn.Sequential(
nn.ConvTranspose2d(32, 16, 3, stride=2, output_padding=0),
nn.BatchNorm2d(16),
nn.ReLU(True),
nn.ConvTranspose2d(16, 8, 3, stride=2, padding=1, output_padding=1),
nn.BatchNorm2d(8),
nn.ReLU(True),
nn.ConvTranspose2d(8, 1, 3, stride=2, padding=1, output_padding=1),
)
def forward(self, x):
x = self.decoder_lin(x)
x = self.unflatten(x)
x = self.decoder_conv(x)
x = torch.sigmoid(x)
return x
Parent Class
class VariationalAutoEncoder(nn.Module):
def __init__(self, latent_dimensions):
super().__init__()
self.encoder = VariationalEncoder(latent_dimensions)
self.decoder = Decoder(latent_dimensions)
# set default floating point data type to float64
torch.set_default_dtype(torch.float64)
def forward(self, x):
z = self.encoder(x)
return self.decoder(z)
Training Loop
def train_epoch(vae, dataloader, optimizer):
# Set train mode
vae.train()
vae.encoder.train()
vae.decoder.train()
train_loss = 0.0
# set_trace()
for x in tqdm(dataloader):
# Get model output
optimizer.zero_grad()
# x = torch.from_numpy(x)
x_hat = vae(x)
# Evaluate loss
loss = torch.sum((x - x_hat) ** 2) + vae.encoder.KLDivergence
# Backward pass
loss.backward()
optimizer.step()
# Print batch loss
# print(f"\t partial training loss (single batch): {loss.item()} ")
train_loss += loss.item()
return train_loss / len(dataloader.dataset)
Thank you for your time!