I was experimenting with the iter and next functionality to iterate through my dataloader.
When I train the model using iter,it seems that I am only processing one batch of the trainloader
as shown in the below log
torch.Size([16, 3, 512, 512])
Epoch : 1 Train Loss : 0.001343
torch.Size([16, 3, 512, 512])
Epoch : 2 Train Loss : 0.002819
torch.Size([16, 3, 512, 512])
Epoch : 3 Train Loss : 0.004004
torch.Size([16, 3, 512, 512])
Epoch : 4 Train Loss : 0.005313
torch.Size([16, 3, 512, 512])
Epoch : 5 Train Loss : 0.006345
torch.Size([16, 3, 512, 512])
Epoch : 6 Train Loss : 0.007257
torch.Size([16, 3, 512, 512])
Epoch : 7 Train Loss : 0.008262
torch.Size([16, 3, 512, 512])
Epoch : 8 Train Loss : 0.009080
torch.Size([16, 3, 512, 512])
Epoch : 9 Train Loss : 0.010034
torch.Size([16, 3, 512, 512])
Epoch : 10 Train Loss : 0.011135
My training code is as follows
epochs_a=10
criterion=nn.L1Loss()
optimizer=torch.optim.Adam(model.parameters(),lr = lr)
iter_source=iter(train_loader)
train_loss=0.0
for i in range(epochs_a):
model.train()
optimizer.zero_grad()
images=iter_source.next()
image=images[0].to(device)
print(image.shape)
labels=images[1].to(device)
logits=model(image)
loss=criterion(logits,labels)
loss.backward()
optimizer.step()
train_loss+=loss.item()
print("Epoch : {} Train Loss : {:.6f} ".format(i+1, train_loss/len(train_loader)))
But when I use a simple enumerate or tqdm to iterate through the trainloader as shown in the below code
criterion=nn.L1Loss()
optimizer=torch.optim.Adam(model.parameters(),lr = lr)
def train_batch_loop(model,trainloader):
train_loss = 0.0
train_acc = 0.0
for images,labels in tqdm(trainloader):
# move the data to CPU
images = images.to(device)
labels = labels.to(device)
logits = model(images)
loss = criterion(logits,labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
return train_loss / len(trainloader)
epochs_a=10
for i in range(epochs_a):
model.train()
avg_train_loss=train_batch_loop(model,train_loader)
print("Epoch : {} Train Loss : {:.6f} ".format(i+1, avg_train_loss))
Then I am able to go through all 400 batches ,and the training log looks like this
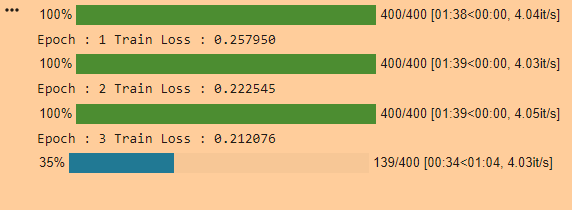
So what is the difference between the two codes,and how can I use iter and next to go through all 400 batches rather than just one single batch