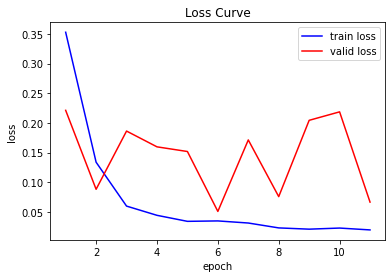
- I tried the following debugging in the same setting.
1). pos_weight <0; 0.2 scale
2). pos_weight = None
3). pos_weight >= 1; scale 10 1 to 100
As a result,
In 1) confirmed that the loss value decreased similarly for both train and valid, but it was confirmed that the confusion matrix and dice values did not improve each epoch.
In 2), I saw a lot of changes in both train loss and valid loss.
In 3), similar to the graph in the question, train loss decreased well, but valid loss changed significantly.
I think the 3) case is appropriate, but I wonder if there are other factors that reduce the fluctuation of valid?
- I configured the code as below to use
WeightedRandomSampler, but I am not sure how to load the target because I am using concat dataset.
train_datasets = []
for i in range(5):
secure_random = random.SystemRandom()
random_patient = secure_random.choice(patient_index)
train_datasets.append(trainDataset(random_patient,"data_path",augmentation=True))
patient_index.remove(random_patient)
traindataset = torch.utils.data.ConcatDataset(train_datasets)
class_sample_count = [neg,pos] # I already calculated negative/positive count
weights = 1/torch.tensor(class_sample_count, dtype=torch.float)
samples_weights = [weights[t] for t in target]
sampler = torch.utils.data.sampler.WeightedRandomSampler(weights=samples_weights, num_samples=len(samples_weights, replacement=True)
data_loader = torch.utils.data.DataLoader ....
Is there a way to load the target in this code samples_weights = [weights[t] for t in target]?
My custom dataset (=trainDataset) follows the structure below.
class trainDataset(torch.utils.data.Dataset):
def __init__(self, i, data_path, augmentation=True):
self.data_path = data_path
self.data = np.load(data_path)
self.target = np.load(target_path).astype(np.uint8)
self.data = self.data-self.data.mean()
self.data = self.data/self.data.std()
self.augmentation = augmentation
def __getitem__(self, index):
x = self.data[index]
y = self.target[index]
x, y = self.transform(x, y)
return x, y
def transform(self, data, target):
data, target = data_augmentation(data, target, self.augmentation)
return data, target
def __len__(self):
return len(self.data)
- In my think, if I use
WeightedRandomSampler, use of pos_weight doesn’t seem to make sense. Is this correct?
Thanks!