Glad that this was useful, but please note that this particular code example is ~1.5 years old (might have been the very, very first version of PyTorch, PyTorch 0.1).
In PyTorch 0.4, it’s not necessary to wrap everything into a “Variable” anymore. Below, I updated the code accordingly:
OLD:
from torch.autograd import Variable
import torch
x = Variable(torch.Tensor([[1.0, 1.0],
[1.0, 2.1],
[1.0, 3.6],
[1.0, 4.2],
[1.0, 6.0],
[1.0, 7.0]]))
y = Variable(torch.Tensor([1.0, 2.1, 3.6, 4.2, 6.0, 7.0]))
weights = Variable(torch.zeros(2, 1), requires_grad=True)
for i in range(5000):
net_input = x.mm(weights)
loss = torch.mean((net_input - y)**2)
loss.backward()
weights.data.add_(-0.0001 * weights.grad.data)
if loss.data[0] < 1e-3:
break
print('n_iter', i)
print(loss.data[0])
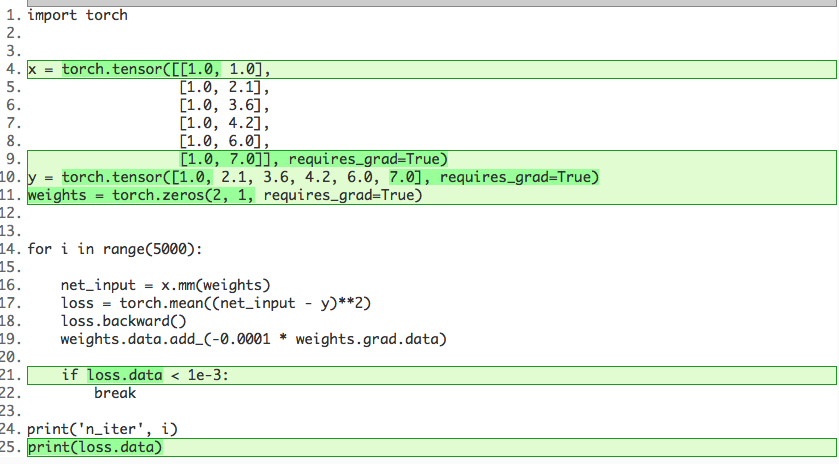
NEW:
import torch
x = torch.tensor([[1.0, 1.0],
[1.0, 2.1],
[1.0, 3.6],
[1.0, 4.2],
[1.0, 6.0],
[1.0, 7.0]], requires_grad=True)
y = torch.tensor([1.0, 2.1, 3.6, 4.2, 6.0, 7.0], requires_grad=True)
weights = torch.zeros(2, 1, requires_grad=True)
for i in range(5000):
net_input = x.mm(weights)
loss = torch.mean((net_input - y)**2)
loss.backward()
weights.data.add_(-0.0001 * weights.grad.data)
if loss.data < 1e-3:
break
print('n_iter', i)
print(loss.data)
DIFF between OLD and NEW: