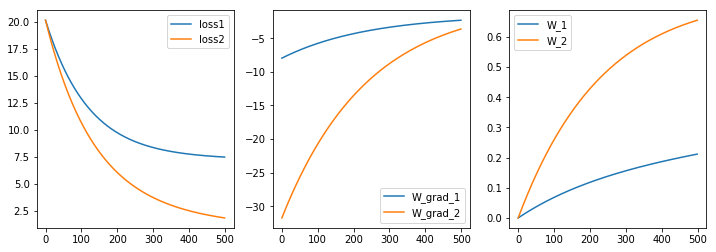
I was reading through the tutorials but I feel like I still don’t quite understand how torch.nn.Module works. Again, as the simplest possible toy example for exploring the API, I tried to implement OLS regression.
Essentially, I want to reproduce the results I get when I do it “manually:”
from torch.autograd import Variable
import torch
x = Variable(torch.Tensor([[1.0, 1.0],
[1.0, 2.1],
[1.0, 3.6],
[1.0, 4.2],
[1.0, 6.0],
[1.0, 7.0]]))
y = Variable(torch.Tensor([1.0, 2.1, 3.6, 4.2, 6.0, 7.0]))
weights = Variable(torch.zeros(2, 1), requires_grad=True)
for i in range(5000):
net_input = x.mm(weights)
loss = torch.mean((net_input - y)**2)
loss.backward()
weights.data.add_(-0.0001 * weights.grad.data)
if loss.data[0] < 1e-3:
break
print('n_iter', i)
print(loss.data[0])
Output:
n_iter 1188
0.0004487129335757345
Now, running the following
import torch.nn.functional as F
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.weights = Variable(torch.zeros(2, 1),
requires_grad=True)
def forward(self, x):
net_input = x.mm(self.weights)
return net_input
model = Model()
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
raises an error:
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-258-3bcb3a8408d2> in <module>()
15 model = Model()
16 criterion = torch.nn.MSELoss()
---> 17 optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
/Users/Sebastian/miniconda3/envs/pytorch/lib/python3.5/site-packages/torch/optim/sgd.py in __init__(self, params, lr, momentum, dampening, weight_decay)
24 defaults = dict(lr=lr, momentum=momentum, dampening=dampening,
25 weight_decay=weight_decay)
---> 26 super(SGD, self).__init__(params, defaults)
27
28 def step(self, closure=None):
/Users/Sebastian/miniconda3/envs/pytorch/lib/python3.5/site-packages/torch/optim/optimizer.py in __init__(self, params, defaults)
25 self.state = defaultdict(dict)
26 self.param_groups = list(params)
---> 27 if not isinstance(self.param_groups[0], dict):
28 self.param_groups = [{'params': self.param_groups}]
29
IndexError: list index out of range
So, would I need a layer in forward to make it work?
I tried that:
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.weights = Variable(torch.zeros(2, 1),
requires_grad=True)
self.fc = torch.nn.Linear(2, 1)
def forward(self, x):
return x
model = Model()
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.0001)
for i in range(5000):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
print(loss.data[0])
but now, I am getting an error about the dimensions of the input:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-259-c6bb483f3953> in <module>()
28 outputs = model(x)
29
---> 30 loss = criterion(outputs, y)
31 loss.backward()
32
/Users/Sebastian/miniconda3/envs/pytorch/lib/python3.5/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
208
209 def __call__(self, *input, **kwargs):
--> 210 result = self.forward(*input, **kwargs)
211 for hook in self._forward_hooks.values():
212 hook_result = hook(self, input, result)
/Users/Sebastian/miniconda3/envs/pytorch/lib/python3.5/site-packages/torch/nn/modules/loss.py in forward(self, input, target)
21 _assert_no_grad(target)
22 backend_fn = getattr(self._backend, type(self).__name__)
---> 23 return backend_fn(self.size_average)(input, target)
24
25
/Users/Sebastian/miniconda3/envs/pytorch/lib/python3.5/site-packages/torch/nn/_functions/thnn/auto.py in forward(self, input, target)
39 output = input.new(1)
40 getattr(self._backend, update_output.name)(self._backend.library_state, input, target,
---> 41 output, *self.additional_args)
42 return output
43
RuntimeError: input and target have different number of elements: input[6 x 2] has 12 elements, while target[6] has 6 elements at /Users/soumith/anaconda/conda-bld/pytorch-0.1.6_1484801351127/work/torch/lib/THNN/generic/MSECriterion.c:12
So, I was looking into torch.nn.Linear(2, 1), and it seems to just return the input array in forward, however, in the documentation, it says "Applies a linear transformation to the incoming data: :math:y = Ax + b".
It would be great if someone could help me a bit with regard to what’s going on here and how to use the nn.Module correclty.
Best,
Sebastian

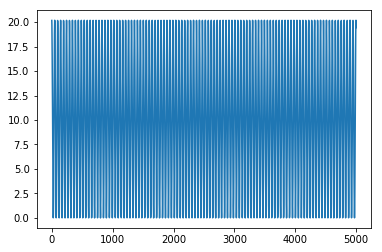

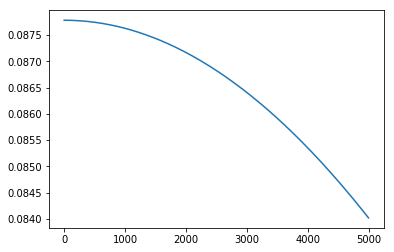


 -> Oh, well, there are two input neurons and just one output neuron. So, yeah, it is symmetric to itself, ha.
-> Oh, well, there are two input neurons and just one output neuron. So, yeah, it is symmetric to itself, ha.