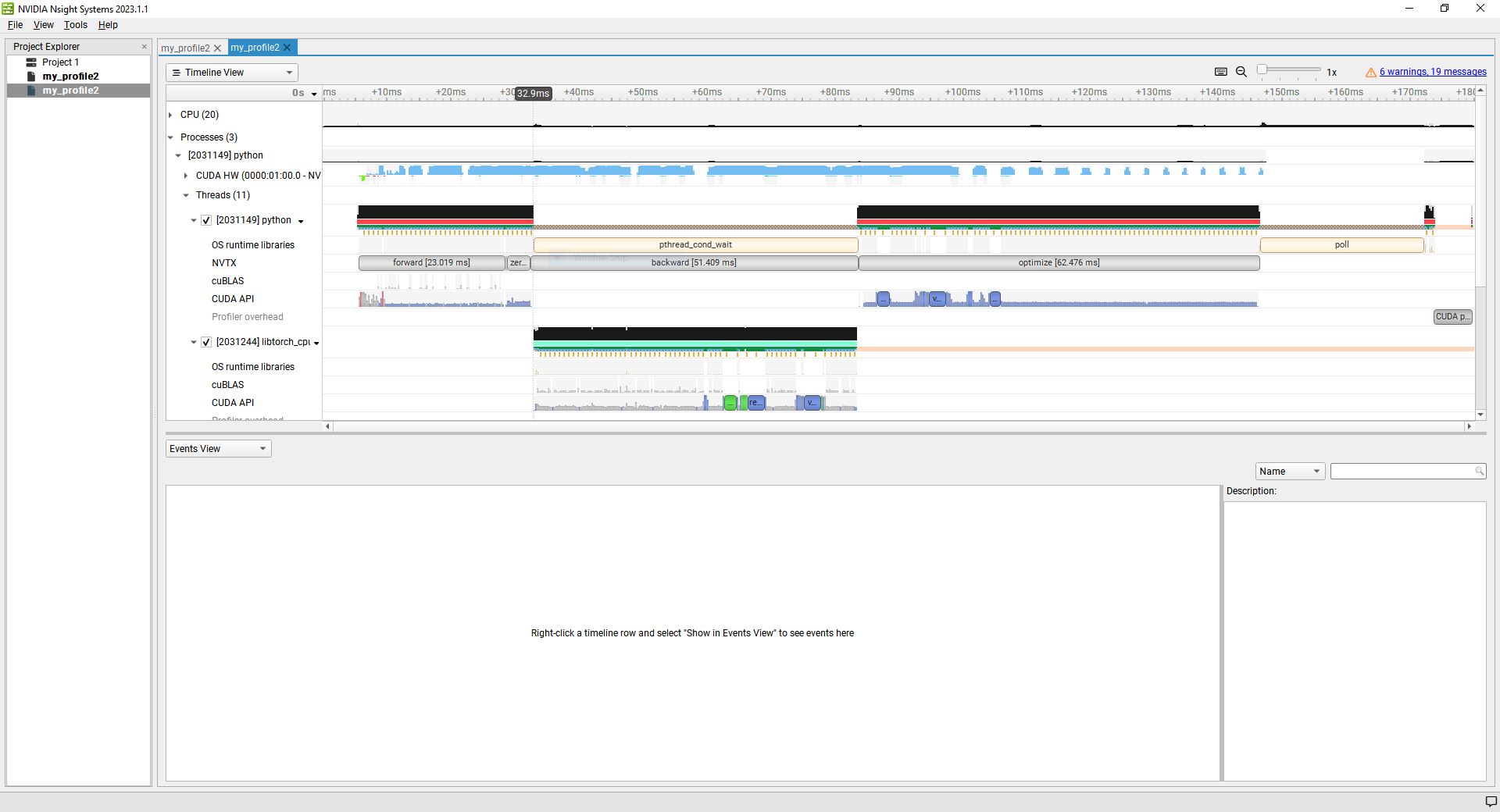
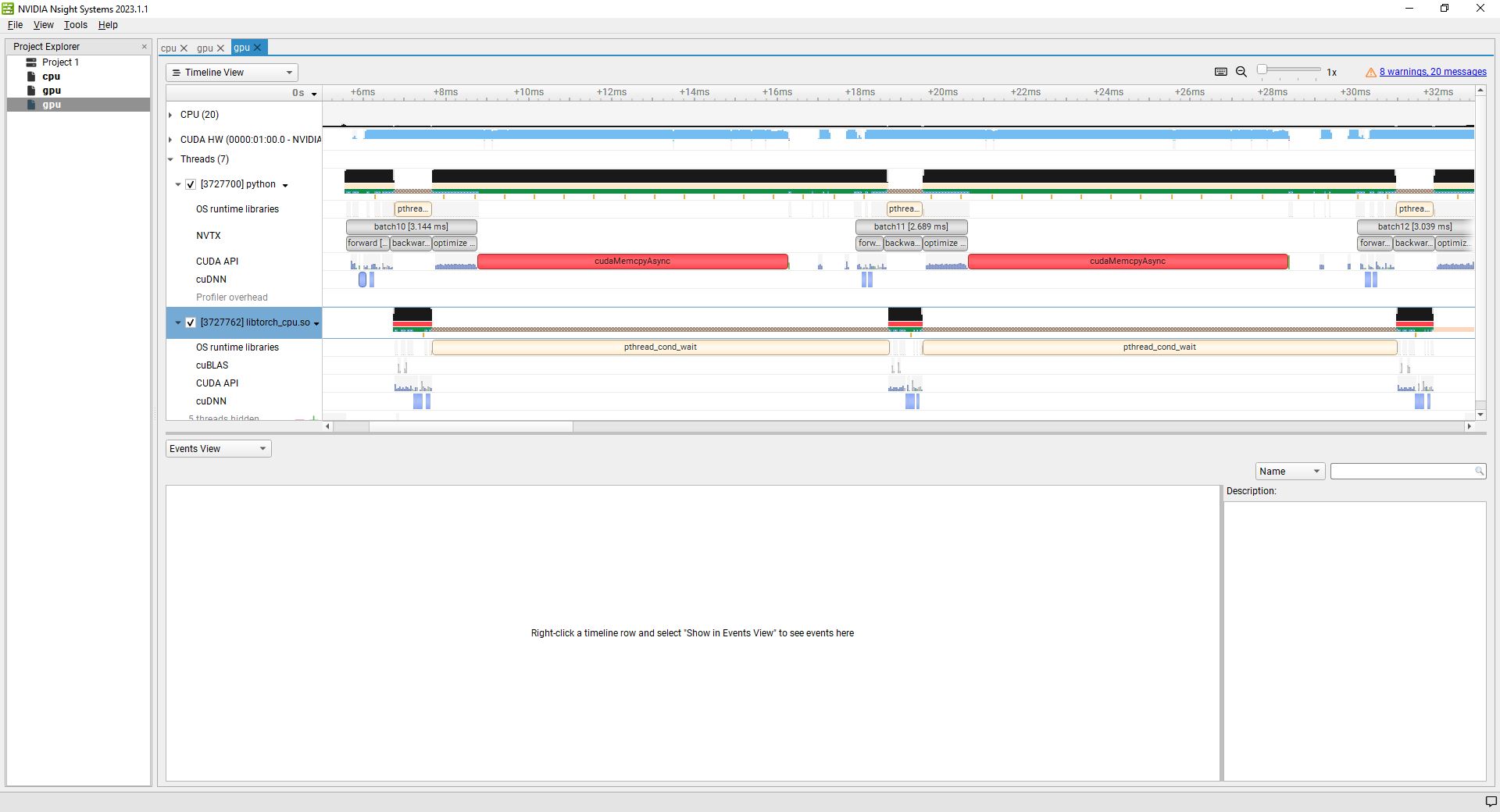
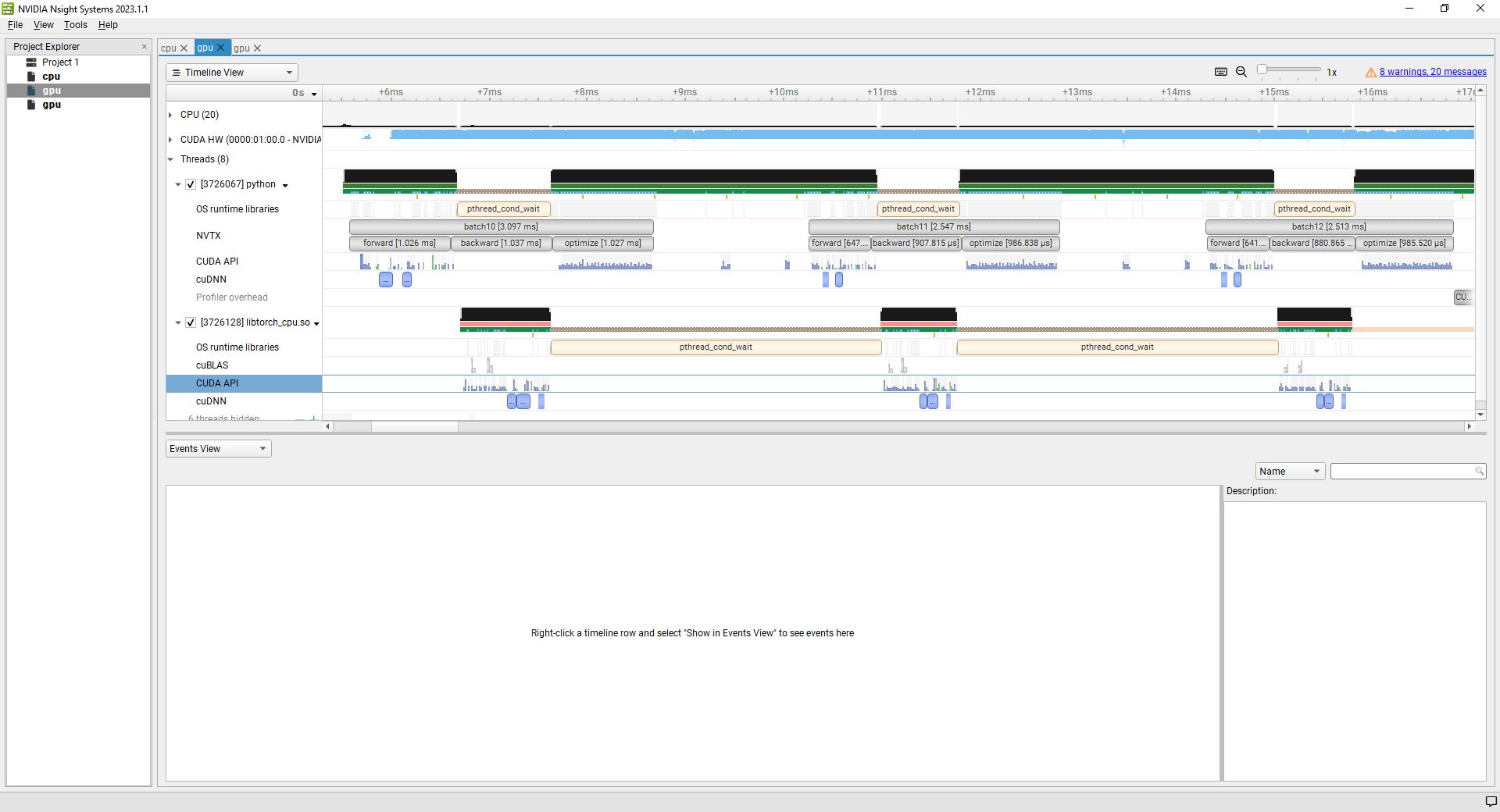
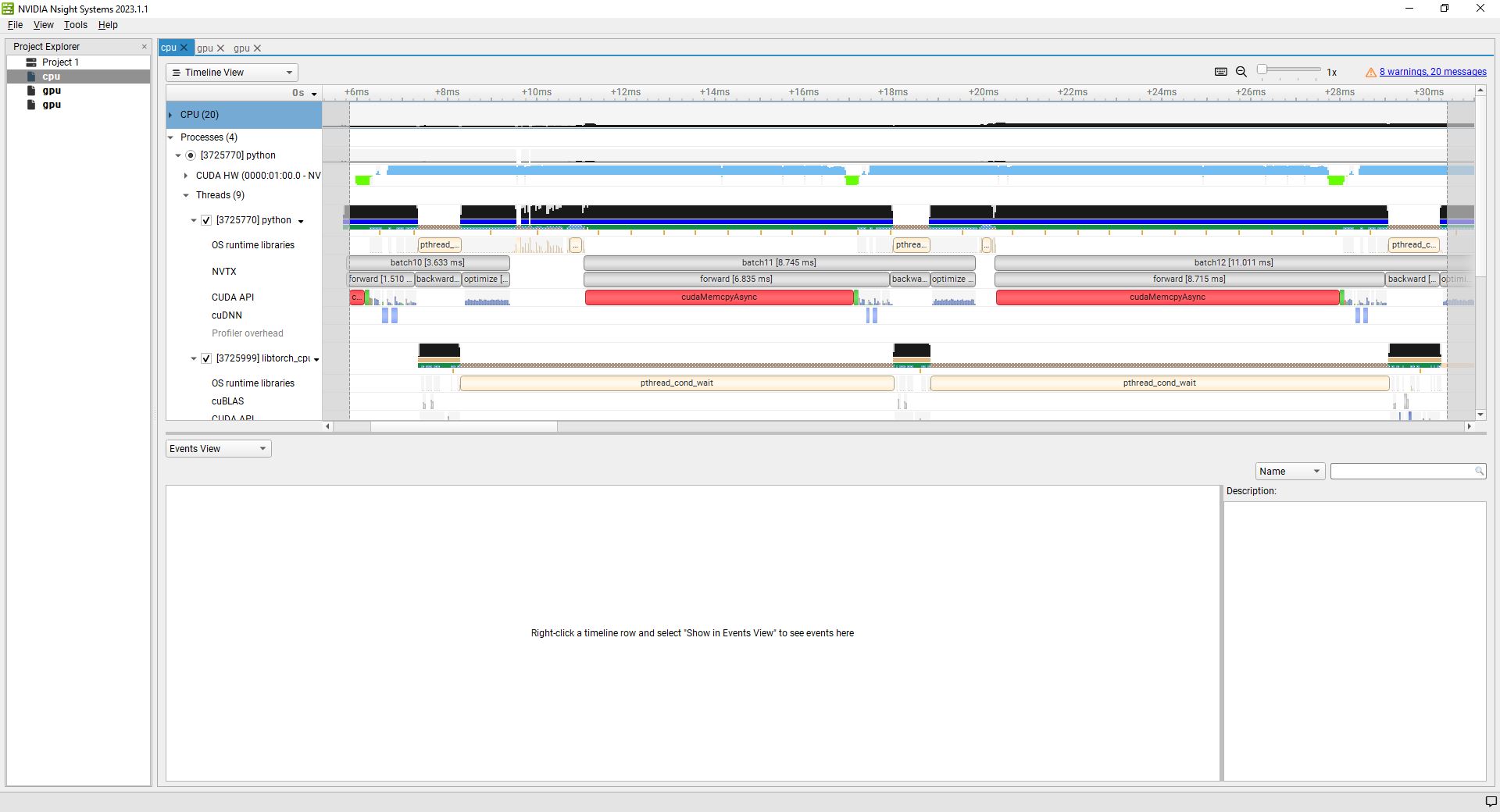
Hello again! The project I am trying to optimize is a little more complicated, so I decided to try some tests on a very simple project, specifically the well-known MNIST network. What I want to see is whether it too uses 100% cpu when running with 1) tensors preloaded to to the gpu and 2) worker-threads moving tensors from cpu to gpu. In my main project, I can fit all of the data on the gpu so I assumed that this was the fastest way to do things, but as I mentioned before, nothing I do seems to make a difference because it appears to be cpu-limited (and I’m not sure why).
With the MINST project, I do see more expected results. Preloading the tensors results in a long startup time and then a slightly faster per-epoch speed. But as I increase the #workers this speed gap becomes somewhat insignificant when compared to the cpu-to-gpu method (eg with 8 worker threads it’s almost the same). I’m assuming that at some point the gpu becomes the rate limiting step.
However, I am having trouble understanding the profile. I will attach the pictures below. The profile I am using is:
nsys profile -w true -t cuda,nvtx,osrt,cudnn,cublas -s cpu --force-overwrite true --capture-range=cudaProfilerApi --capture-range-end=stop --cudabacktrace=true -x true -o cpu python test.py # or gpu python test.py gpu for the gpu version
Code:
import sys
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def train(model, device, train_loader, optimizer):
model.train()
batch_start = 10
batch_end = 12
for batch_idx, (data, target) in enumerate(train_loader):
# print a few batches
save = batch_idx>=batch_start and batch_idx<=batch_end
if save:
if batch_idx==batch_start:
torch.cuda.cudart().cudaProfilerStart()
start = time.time()
torch.cuda.nvtx.range_push("batch"+str(batch_idx))
torch.cuda.nvtx.range_push("forward")
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
if save:
torch.cuda.nvtx.range_pop() #forward
torch.cuda.nvtx.range_push("backward")
loss.backward()
if save:
torch.cuda.nvtx.range_pop() #backward
torch.cuda.nvtx.range_push("optimize")
optimizer.step()
if save:
torch.cuda.nvtx.range_pop() #optimize
torch.cuda.nvtx.range_pop() #batch
if batch_idx==batch_end:
print(time.time()-start,"seconds")
torch.cuda.cudart().cudaProfilerStop()
print('[{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))
def main():
torch.manual_seed(0)
device = torch.device("cuda")
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset = datasets.MNIST('data', train=True, transform=transform)
if len(sys.argv)>1 and sys.argv[1] == 'gpu':
print("Preloading data to gpu..")
# create a new dataset on the gpu
# MNIST data set is format [image as Tensor, target id as int]
gpu_dataset = []
for x,y in dataset:
gpu_dataset.append((x.to(device),torch.tensor(y,dtype=torch.int64,device=device)))
dataset = gpu_dataset
num_workers = 0
else:
print("Using workers for cpu...")
num_workers = 8
train_loader = torch.utils.data.DataLoader(dataset,batch_size=1000,num_workers=num_workers,shuffle=True)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=1.0)
train(model, device, train_loader, optimizer)
if __name__ == '__main__':
main()