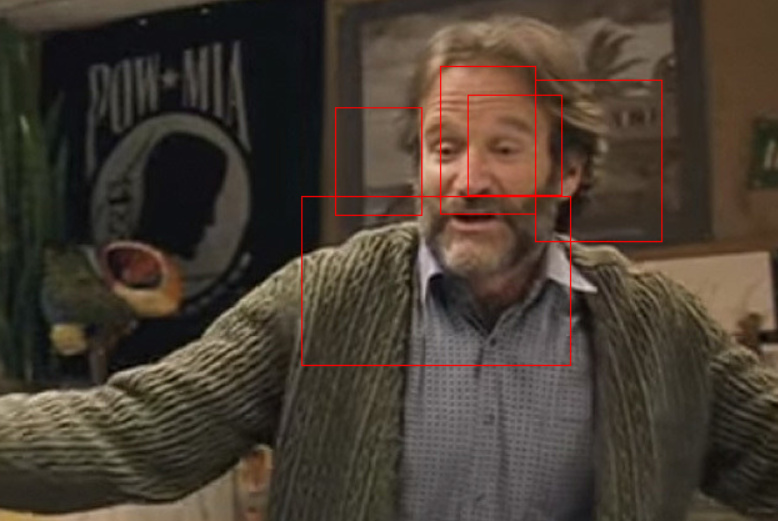
I’ve been working on building a facial detection NN through fine-tuning the pretrained Faster RCNN. I have been able to get boxes to populate in the general area of faces, but it is very hit or miss. I thought that a normalization transformation would give me better results but when I did the transformation my images come out like this:
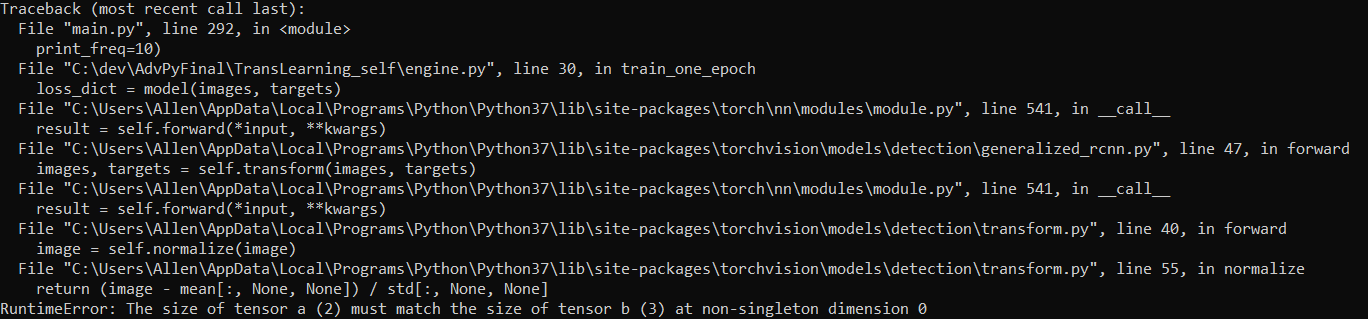
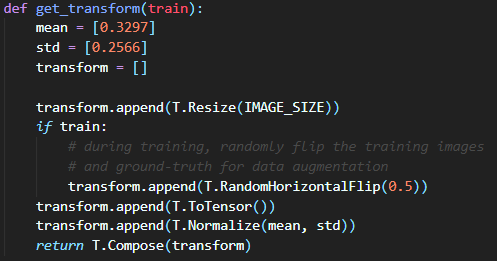
My thought is, maybe the normalization transform is being called twice? Once in the Faster RCNN source code and then once by me. The reason I think it is being called twice is because I received a tensor mismatch error, when I tried changing my images to gray scale when I loaded them in. This same exact error occurred both with and without my Normalization transform.