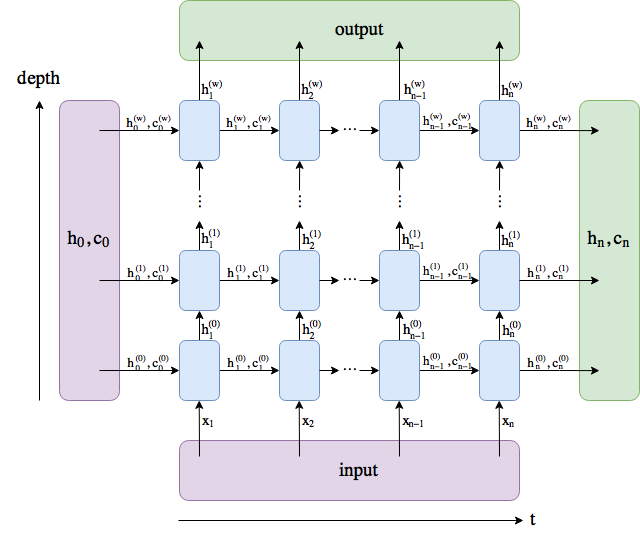
I have not had much experience with RNNs and have been looking at some examples in the pytorch repository and I have a question about the example provided here: https://github.com/pytorch/examples/blob/master/word_language_model/model.py
In this example, the RNNModel forward function looks as follows:
def forward(self, input, hidden):
emb = self.drop(self.encoder(input))
output, hidden = self.rnn(emb, hidden)
output = self.drop(output)
decoded = self.decoder(output)
return decoded, hidden
I have 2 questions:
1: Why is the output being used in the decoder step? I thought the decoder should take the hidden state as input? Should this not be self.decoder(hidden)?
2: Assuming there is an explanation for (1), why is usually the dropout used on the output? I am guessing the output here is a tensor. So, how is dropout applied on a tensor? I thought dropout is a property of the weights?
I hope my questions make some sense.