If you want to get a helpful answer, you should explain what you’re trying to do, how and why did you plot these diagrams and what you expected to see in them.
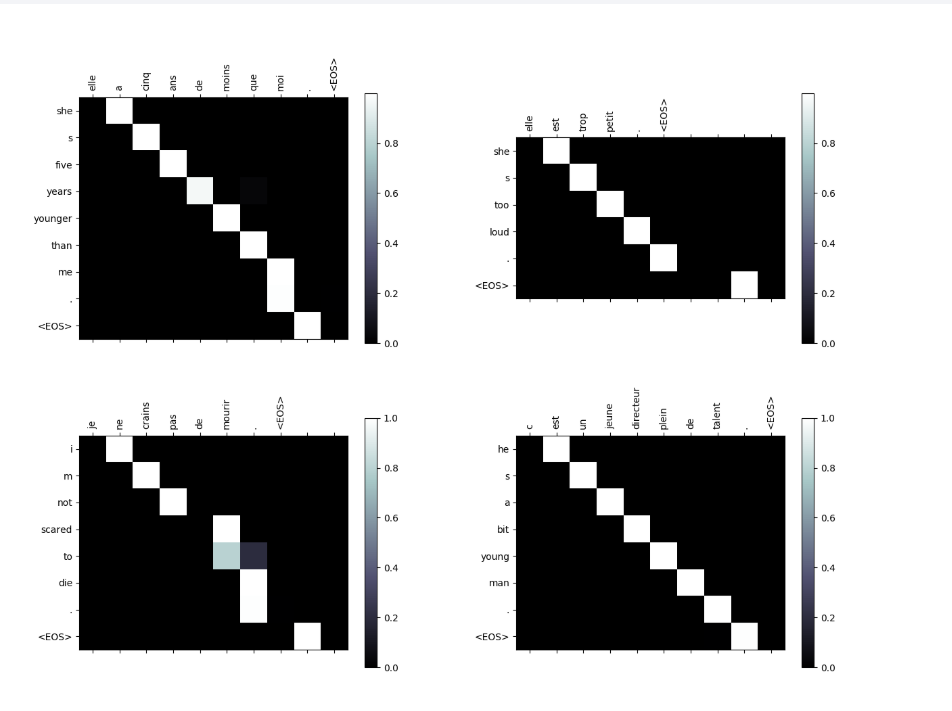
From a purely linguistic perspective, it looks like the diagram was shifted “one block” to the right.
Also, what direction are you translating into? Because there are nonsensical sentences in both english and french (“elle est trop petit” has wrong grammatical agreement, “he’s a bit young man” doesn’t make sense…).
It’s surprising as well that you get mostly 1.0 values throughout the diagrams, there doesn’t seem to be a lot of variation in the values, except for the third sentence pair…
Ho it’s the attention maps from the NLP tutorial ! ok.
I am not a specialist of this, @spro correct me if I’m wrong here !
I think the model not not trained to see the difference between “petit” and “petite” in french and “petit” is considered correct for both. This would be to reduce the size of the dictionary.
There maps show, when using the attention model, which part of the input was used to produce each output. What it shows is that in most cases, only the previous word of the input is enough to produce the next word in the output. But there are some cases where a given word is used to output multiple outputs or a combination of two input words is used for one output word.
This is run on a small dataset and the model may be overfitting to the dataset: If every time you have a “cinq” you should output “five”, then there is no reason to look at other part of the sentence.