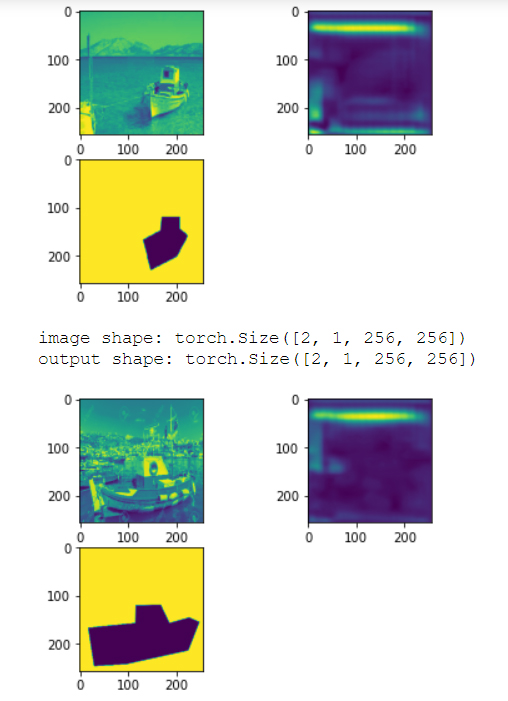
Hello! I am new in Pytorch and I am trying to implement a UNet. I am using some random pictures and their masks from 2 folders with the same names. I followed the implementation from the original paper. Since I am finding the choice of channels very confusing(I have no idea how to go from a 300*300 image to a mask of the same size) I did a workaround and reshaped the ground truth masks to a smaller size. Now the network seems to work but the loss is huge and I am wondering why this is the case.(By the way, I also use very few images-24 in total)
Here is my code:
Loading the data
#get all image and mask paths
image_paths = glob.glob("C:\\Users\\Alexandra\\Desktop\\thesis\\7_week\\data\\img\\*.jpg")
mask_paths = glob.glob("C:\\Users\\Alexandra\\Desktop\\thesis\\7_week\\data\\msk\\*.jpg")
#split paths
len_images = len(image_paths)
print(len_images)
train_size = 0.6
#length of image and mask folder is the same
train_image_paths = image_paths [:int(len_images*train_size)]
test_image_paths = image_paths[int(len_images*train_size):]
train_mask_paths = mask_paths [:int(len_images*train_size)]
test_mask_paths = mask_paths[int(len_images*train_size):]
Dataset:
#dataset class
class image_dataset(Dataset):
def __init__(self, images, masks, train=True):
self.images = images
self.masks = masks
# self.num_classes = num_classes
# self.transforms = transforms
def transform(self, image,mask):
resize_im = transforms.Resize(size = (300,300))
resize_m = transforms.Resize(size = (116,116))
gray = transforms.Grayscale(num_output_channels=1)
image = resize_im(image)
mask = resize_m(mask)
image = gray(image)
mask = gray(mask)
####
image = TF.to_tensor(image)
mask = TF.to_tensor(mask)
return image,mask
def __getitem__(self, idx):
image = Image.open(self.images[idx])
mask = Image.open(self.masks[idx])
x,y = self.transform(image,mask)
return x,y
def __len__(self):
return len(self.images)
train_data = image_dataset(train_image_paths, train_mask_paths, train=True)
train_loader = DataLoader(train_data, batch_size = 2, shuffle = True)
test_data = image_dataset(test_image_paths, test_mask_paths, train = False)
test_loader = DataLoader(test_data, batch_size = 2, shuffle = False)
The network
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
self.maxpool = nn.MaxPool2d(kernel_size =2, stride =2)
#convolutions
self.down_conv1 = Conv_double(1,64)
self.down_conv2 = Conv_double(64, 128)
self.down_conv3 = Conv_double(128, 256)
self.down_conv4 = Conv_double(256, 512)
self.down_conv5 = Conv_double(512, 1024)
#up-convolutions
self.conv_trans1 = nn.ConvTranspose2d(in_channels = 1024, out_channels = 512, kernel_size=2, stride=2)
self.up_conv1 = Conv_double(1024, 512)
self.conv_trans2 = nn.ConvTranspose2d(in_channels = 512, out_channels = 256, kernel_size=2, stride=2)
self.up_conv2 = Conv_double(512, 256)
self.conv_trans3 = nn.ConvTranspose2d(in_channels = 256, out_channels = 128, kernel_size=2, stride=2)
self.up_conv3 = Conv_double(256, 128)
self.conv_trans4 = nn.ConvTranspose2d(in_channels = 128, out_channels = 64, kernel_size=2, stride=2)
self.up_conv4 = Conv_double(128, 64)
#output
self.out = nn.Conv2d(in_channels = 64, out_channels = 1,kernel_size=1)
def forward(self, img):
#bs,c,h,w
#encoder
x1 = self.down_conv1(img) #
x2 = self.maxpool(x1)
x3 = self.down_conv2(x2) #
x4 = self.maxpool(x3)
x5 = self.down_conv3(x4) #
x6 = self.maxpool(x5)
x7 = self.down_conv4(x6) #
x8 = self.maxpool(x7)
x9 = self.down_conv5(x8)
#decoder
x = self.conv_trans1(x9)
#crop tensor
y = Crop_tensor(x7, x)
#conacatenate
x = self.up_conv1(torch.cat([x,y],1))
x = self.conv_trans2(x)
y = Crop_tensor(x5, x)
# print(x5.size())
# print(y.size())
x = self.up_conv2(torch.cat([x,y],1))
x = self.conv_trans3(x)
y = Crop_tensor(x3, x)
x = self.up_conv3(torch.cat([x,y],1))
x = self.conv_trans4(x)
y = Crop_tensor(x1, x)
x = self.up_conv4(torch.cat([x,y],1))
x = self.out(x)
print(x.size())
return x
def Conv_double(in_chans, out_chans):
conv = nn.Sequential(
nn.Conv2d(in_chans,out_chans, kernel_size =3),
nn.ReLU(inplace = True),
nn.Conv2d(out_chans, out_chans, kernel_size =3),
nn.ReLU(inplace=True)
)
return conv
def Crop_tensor(source, target):
target_size = target.size()[2]
source_size = source.size()[2]
d = source_size - target_size
# if d>1:
# d = (int)(d // 2)
# return source[:,:,d:source_size-d, d:source_size-d]
# else:
return source[:,:,d:source_size, d:source_size]
Training loop
model = UNet()
model = model.to(device)
learning_rate = 0.00002
criterion = torch.nn.NLLLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
epochs = 500
total_steps = len(train_loader)
#print(f"{epochs} epochs, {total_steps} total_steps per epoch")
for epoch in range(epochs):
for i, (images, masks) in enumerate(train_loader):
#images_batch = torch.from_numpy(np.array(images))
# masks_batch = torch.from_numpy(np.array(masks))
images = images.to(device)
masks = masks.type(torch.LongTensor)
# masks = masks.reshape(masks.shape[0], masks.shape[2], masks.shape[3])
masks = masks.to(device)
#print(images.shape)
# Forward pass
outputs = model(images)
softmax = torch.nn.functional.log_softmax(outputs, dim=1)
loss = criterion(outputs, masks.squeeze())
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i) % 100 == 0:
print (f"Epoch [{epoch + 1}/{epochs}], Step [{i}/{total_steps}], Loss: {loss.item():4f}")
And in epoch 3 I get “Epoch [3/500], Step [0/14], Loss: -22895850.000000” for example
Any ideas what is wrong?
Thank you in advance!
*Sorry for the long post, but maybe it will be useful to someone…