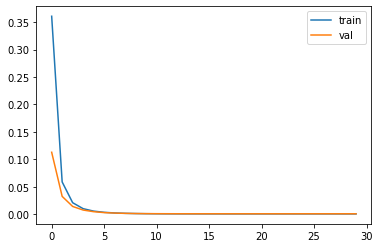
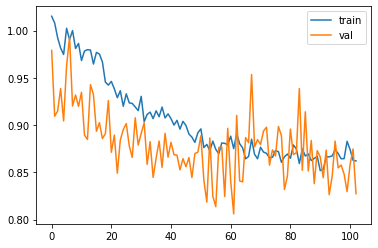
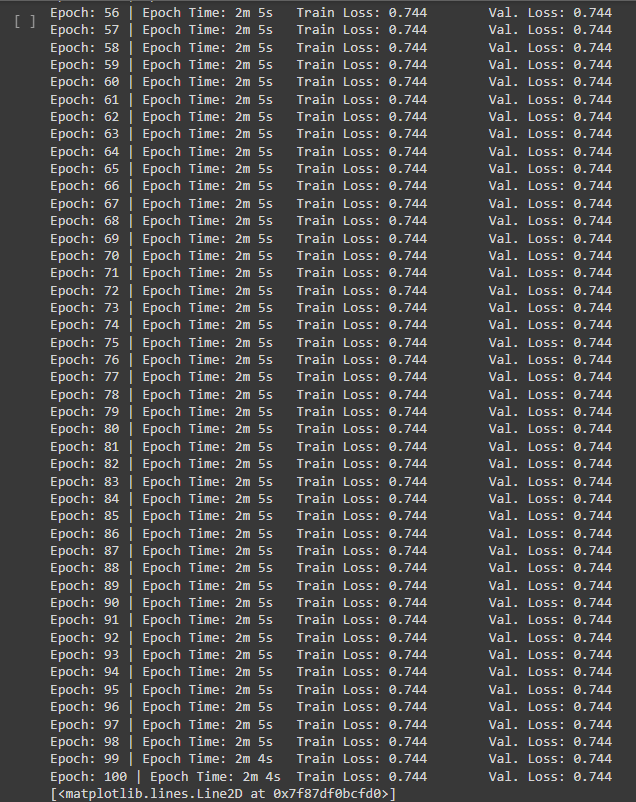
Problem: UNet model is not learning even after100 epochs. It shows the same loss for both training and validation.
Background information:
Each pixel of the Image can have only one label (in total 4 classes as 0,1,2, or 3).
From the DataSet:
BEFORE TRANSFORMATION:
→ label shape from OCTDataset: (496, 512)
→ img shape from OCTDataset: (496, 512)
→ image dtype from OCTDataset: float32, label dtype from OCTDataset: float32
AFTER TRANSFORMATION:
→ shape just after transform of the label: torch.Size([1, 512, 512])
–>shape just after transform of the img: torch.Size([1, 512, 512])
–>image dtype after transform: torch.float32, label dtype after transform: torch.float32
My UNet Model:
##### U-Net Model
##
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(DoubleConv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, 1, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, 1, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
def forward(self, x):
return self.conv(x)
class UNET(nn.Module):
def __init__(
self, in_channels=1, out_channels=3, features=[64, 128, 256, 512],
):
super(UNET, self).__init__()
self.ups = nn.ModuleList()
self.downs = nn.ModuleList()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# Down part of UNET
for feature in features:
self.downs.append(DoubleConv(in_channels, feature))
in_channels = feature
# Up part of UNET
for feature in reversed(features):
self.ups.append(
nn.ConvTranspose2d(
feature*2, feature, kernel_size=2, stride=2,
)
)
self.ups.append(DoubleConv(feature*2, feature))
self.bottleneck = DoubleConv(features[-1], features[-1]*2)
self.final_conv = nn.Conv2d(features[0], out_channels, kernel_size=1)
# softmax
self.softmax=nn.Softmax(dim=1)
def forward(self, x):
skip_connections = []
for down in self.downs:
x = down(x)
skip_connections.append(x)
x = self.pool(x)
x = self.bottleneck(x)
skip_connections = skip_connections[::-1]
for idx in range(0, len(self.ups), 2):
x = self.ups[idx](x)
skip_connection = skip_connections[idx//2]
if x.shape != skip_connection.shape:
x = TF.resize(x, size=skip_connection.shape[2:])
concat_skip = torch.cat((skip_connection, x), dim=1)
x = self.ups[idx+1](concat_skip)
return self.softmax(self.final_conv(x))
My code for training:
# Training function
def train(model, loader, optimizer, loss_fn, device):
epoch_loss = 0.0
model.train()
for x, y in loader:
x = x.to(device, dtype=torch.float32)
y = y.to(device, dtype=torch.float32)
optimizer.zero_grad()
y_pred = model(x)
# removing channel from orig label
y = y.squeeze(1)
loss = loss_fn(y_pred, y.type(torch.LongTensor).cuda())
loss.backward()
optimizer.step()
epoch_loss += loss.item()* x.size(0)
epoch_loss = epoch_loss/len(loader)
return epoch_loss
# Evaluation function
def evaluate(model, loader, loss_fn, device):
epoch_loss = 0.0
model.eval()
with torch.no_grad():
for x, y in loader:
x = x.to(device, dtype=torch.float32)
y = y.to(device, dtype=torch.float32)
y_pred = model(x)
# removing channel from orig label
y = y.squeeze(1)
loss = loss_fn(y_pred, y.type(torch.LongTensor).cuda())
epoch_loss += loss.item()* x.size(0)
epoch_loss = epoch_loss/len(loader)
return epoch_loss
""" Hyperparameters """
H = 512
W = 512
size = (H, W)
num_epochs = 100
lr = 1e-4 # 0.001
device = torch.device('cuda') ##
""" Calculate the time taken """
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
class_weight = [0.9851726793996959, 0.005821095764414637, 0.005777171078234721, 0.0032290537576547757] # class weights of whole dataset (before making subset of training, validation, and test dataset)
class_weight_tensor = torch.Tensor(class_weight).to(device, dtype=torch.float32)
model = UNET(in_channels=1, out_channels=4)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=5, verbose=True)
# loss function
loss_fn = nn.CrossEntropyLoss(weight=class_weight_tensor)
# lists to collects data while treaining
best_valid_loss = float("inf")
train_losses_list = list()
# if you want to resume training from check point then change it to True
resume_Training = False
Training loop
""" Training the model """
for epoch in range(num_epochs):
# resume
if resume_Training:
checkpoint = torch.load('/content/drive/MyDrive/Practical_work/May2022/outputs/model_V2.pth')
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
train_losses_list = checkpoint['loss_train_list']
val_losses_list = checkpoint['loss_val_list']
best_valid_loss = val_losses_list[-1]
model.train()
resume_Training = False
start_time = time.time()
train_loss = train(model, oct_trainingloader, optimizer, loss_fn, device = device)
valid_loss = evaluate(model, oct_validationloader, loss_fn, device = device) # epoch_loss, precision, recall, thresholds, iou_val
# append
train_losses_list.append(train_loss)
val_losses_list.append(valid_loss)
""" Saving the model """
if valid_loss < best_valid_loss:
data_str = f"Valid loss improved from {best_valid_loss:2.4f} to {valid_loss:2.4f}. Saving checkpoint"
print(data_str)
best_valid_loss = valid_loss
state = {'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss_train_list': train_losses_list,
'loss_val_list': val_losses_list,
}
torch.save(state, f'/content/drive/MyDrive/Practical_work/May2022/outputs/model_V2.pth')
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
data_str = f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s'
data_str += f'\tTrain Loss: {train_loss:.3f}'
data_str += f'\t Val. Loss: {valid_loss:.3f}'
print(data_str)
# Ploting losses
plt.plot(train_losses_list)
plt.plot(val_losses_list)```