I have a vanilla implementation of UNet, which I want to use for multiclass segmentation (where each pixel can belong to many classes). I am interested in advice on which loss function to select in this application.
This long thread suggests using CrossEntropyLoss at first, before recommending BCELoss. Is one of these methods preferred over the other? Is there some other, better method?
If using CrossEntropy, I assume I can pass in an entire batch at once to calculate the loss, while with BCELoss, I assume I must individually find the loss for each output channel, per image, and sum them together to get an overall loss value. If this is true, BCELoss sounds like a lot more work in this scenario.
Let me distinguish between a (single-label) multi-class problem and
a multi-label, multi-class problem. In both cases you have multiple
classes (one of which might be a “background” or catch-all “other”
class).
In the single-label case, each pixel (or more generally, each item
to be classified) belongs to exactly one class. CrossEntropyLoss
is the natural loss criterion in this case.
In the multi-label case, each pixel belongs to any number of the
classes, including no class or all classes. BCEWithLogitsLoss
is the natural loss criterion to use for a multi-label, multi-class
problem, and it works out of the box for this use case without any
additional fussing around.
You say that “each pixel can belong to many classes,” so I understand
you to be working with a multi-label, multi-class problem.
The multi-label problem should be understood as number-of-classes
binary classification problems all being run in parallel in the same
network. Is the pixel in class-A, yes or no? (a binary problem);
independently, is the pixel in class-B, yes or no? (a second binary
problem); and so on.
(Please note that BCEWithLogitsLoss is to be preferred to BCELoss
for reasons of numerical stability.)
Thanks KFrank. This makes sense to me. I just needed a nudge in the right direction! Thanks also for clarifying multi-class and multi-label problems.
I have a related followup question. BCEWithLogitsLoss seems be working quite well with my dataset (>99% accuracy). However, I am completely missing one of my output channels (the green channel in the below example). It seems like because this class is small in magnitude, compared to the other classes, the network is not learning this class at all.
Would you recommend scaling the class weights for BCEWithLogitsLoss, or perhaps something else? I do not have a background class – just 3 output channels for R, G, B. I create the predicted output image using torch.round(F.sigmoid(model(data))) to force every pixel to 0 or 1 for each class.
I have not used channel scaling or a background channel before, so I’m not sure how to go about doing that.
First, a clarifying question about your multi-class segmentation
problem:
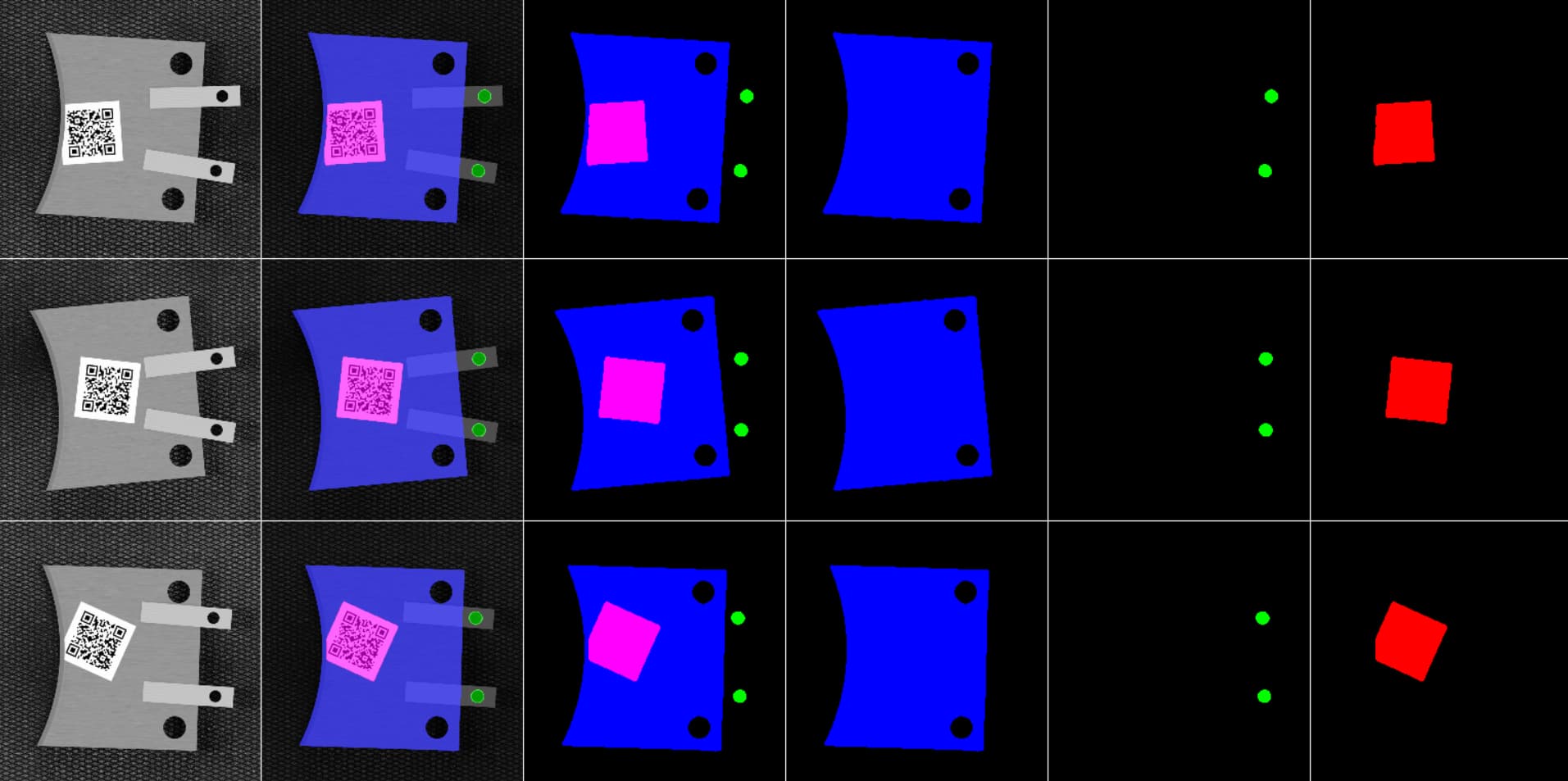
In the “Mask” (and “Predicted”) image you post I see four colors:
black, green, blue, and magenta. You might have other images
with more colors, but it looks to me like you might be performing
single-label, four-class (or perhaps a few more than four-class)
segmentation.
I understand that magenta is made of red and blue, so you could
interpret it as being in the both the “red” class and the “blue” class,
but is there any substantive sense in which the pixels making up
the QR code in your “Image” image are logically both in a “red”
and “blue” class, or did you just happen to label the QR pixels with
magenta in your mask?
Just because you choose to label pixels in your mask with saturated
RGB colors doesn’t mean that your problem is naturally a multi-label,
three-class (RGB) problem. Is it possible that single-label, multi-class
segmentation is a better logical fit for your use case?
Whether you treat this as single-label or multi-label, the fact that one
of your classes (green) is significantly less common than the others
can lead to an otherwise well-trained network not predicting the “rare”
class at all.
Class weights, where you weight the green class more heavily, make
sense in such a case, and both CrossEntropyLoss (for the single-label
case) and BCEWithLogitsLoss (for the multi-label case) support class
weights. A common, sensible approach is to weight each class in
inverse proportion to how often it occurs in your training set.
As a side note, you don’t need to use sigmoid() / round() to convert
your floating-point network output to a binary prediction. Thresholding
against zero, data > 0.0, is equivalent, and I prefer it stylistically.
You are correct that there are only 4 channels (RGB + background as black) in my masks. Each channel/class is binary with the black background as zeros. I have my model setup for only 3 output channels.
I do want to keep the multi-label aspect of this classification so that I can analyze each channel independently in a postprocessing step. So it is important to me that the network learns “class independence”, so to speak (although that might be the wrong term). For instance, I want the network to learn there are “blue plate pixels” under the QR code, so that I can analyze the blue channel without worrying about it having a QR code-shaped hole through it. I want to be able to measure the blue plate characteristics regardless of the QR code or any other overlapping label.
The same logic follows for the other channels, where it’s important to have overlapping segments for this application. I hope that makes sense.
With this in mind, I believe BCEWithLogitsLoss is still the way to go based on your earlier description. However, I’m having some trouble setting up the weights with this loss function (see below). I found this post (from you) that offers some explanation but I’m still confused how to get the weights up and running.
# red, blue, green channel weights = 6, 1, 30
loss_func = nn.BCEWithLogitsLoss(
pos_weight=torch.Tensor([1, 30, 6]).repeat(BATCH_SIZE, 1))
# RuntimeError: The size of tensor a (3) must match the size of
# tensor b (256) at non-singleton dimension 3
Yes, it sounds like you do have a multi-label, three-class problem.
Unfortunately, the documentation for BCEWithLogitsLoss is pretty
much silent about your use case (sometimes called the K dimensional
case in other parts of the pytorch documentation). Specifically, your
prediction (and mask) don’t have shape [nBatch, nChannel], but
instead also have spatial dimensions, so that its shape is all of [nBatch, nChannel, height, width]. That is you are not just
making a multi-label (nChannel) prediction for each sample in the
batch, but for each pixel in the image individually.
In this case, BCEWithLogitsLoss’s weight and pos_weight tensors
(passed in as constructor arguments to BCEWithLogitsLoss) are broadcast over pred and mask (called input and target in the
documentation). Therefore, to make your pos_weight tensor properly
broadcastable, you need to add two singleton dimensions to its end
(that will then be broadcast over the height and width dimensions).
It doesn’t matter how you do this – one way is to use unsqueeze().
Note, mask should be of floating-point type, not integer. Your mask
entries can be exactly 0.0 or 1.0 if you want, but they can be any
value in between, as well.
Unfortunately, the documentation for BCEWithLogitsLoss is pretty
much silent about your use case
Wow, thank you for explaining. What you described is honestly something I would not have figured out by myself reading the docs… For this application, using the right loss function and loss weighting was the critical piece. I don’t think the model learning would have converged without it, even in this simplified MVP. My segmentation is now looking great with extremely high accuracy after I implemented the weighting correctly.