Hi Folks,
I read a paper that they use Unet CNN to build a model using inputs of 870 images size(200x600x1) & 870 label images which is 6-12 layers/classes with the same shape as inputs.
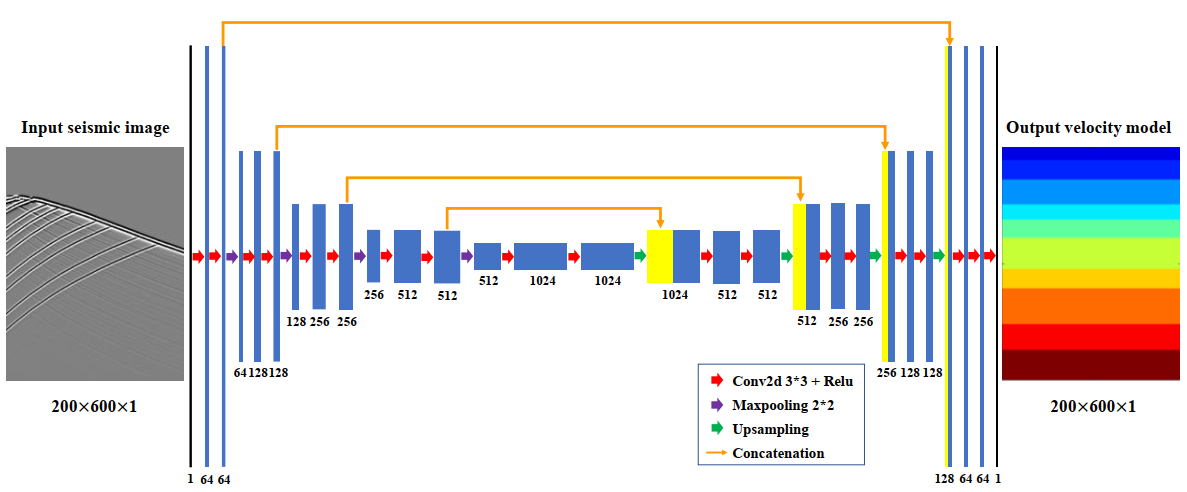
I have several concerns as below:
Is it a multi-class classification (6-12 classes) process (crossentropyloss function) or regression (mean_square_error)?
I just wonder that do they need to build a mask dataset? that is a bridge connect input’s pixels with labels’ pixels. It because I see there is no linear correlation between input & label in term of pixels/color values so far. I still believe that CNN Unet will generate latent features from down-sampling & up-sampling process though kernel & activation functions to come up with the best weight set to predict output, then no need the mask dataset as other semantic/instance segmentation matter?!
I’m new to this field so please correct me if I’m wrong & kindly share your thought to the above question. Thank you very much!