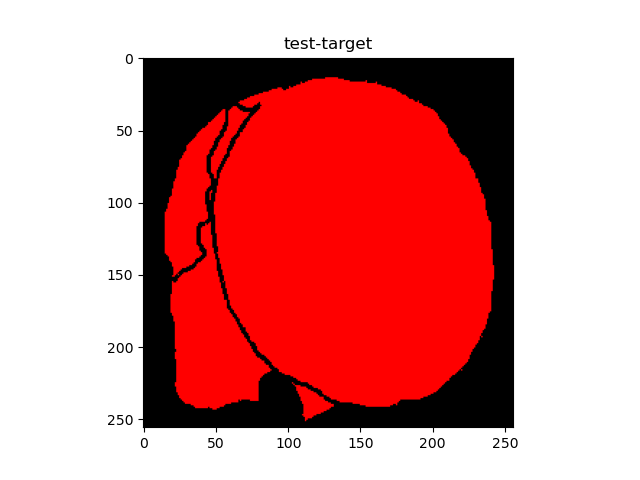
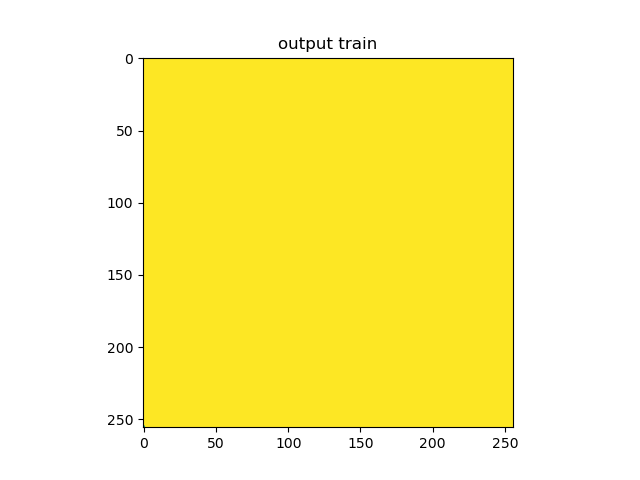
I am building a unet architecture for multiclass classification. The goal is to recognize food on images (eggs, tomato, cheese, etc). I am using Python and Pytorch as library. I have run my train code with my unet architecture but the output prediction is not what i expected. The output show only one class of value 1. Can someone help me with this ? Thanks a lot
the output :
Here is my unet architecture :
def double_conv(in_channels, out_channels):
conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
return conv
class UNet(nn.Module):
def __init__(self, num_classes):
super(UNet, self).__init__()
# definition of max pooling :
self.max_pool_2x2_1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.max_pool_2x2_2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.max_pool_2x2_3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.max_pool_2x2_4 = nn.MaxPool2d(kernel_size=2, stride=2)
# self.max_pool_2x2_5 = nn.MaxPool2d(kernel_size=2, stride=2)
self.down_conv_1 = double_conv(3, 16)
self.down_conv_2 = double_conv(16, 32)
self.down_conv_3 = double_conv(32, 64)
self.down_conv_4 = double_conv(64, 128)
# self.down_conv_5 = double_conv(128, 256)
# self.down_conv_6 = double_conv(256, 512)
# self.up_conv_trans1 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=2, stride=2)
# self.up_conv_1 = double_conv(512, 256)
# self.up_conv_trans2 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=2, stride=2)
# self.up_conv_2 = double_conv(256, 128)
self.up_conv_trans3 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=2, stride=2)
self.up_conv_3 = double_conv(128, 64)
self.up_conv_trans4 = nn.ConvTranspose2d(in_channels=64, out_channels=32, kernel_size=2, stride=2)
self.up_conv_4 = double_conv(64, 32)
self.up_conv_trans5 = nn.ConvTranspose2d(in_channels=32, out_channels=16, kernel_size=2, stride=2)
self.up_conv_5 = double_conv(32, 16)
self.out = nn.Conv2d(in_channels=16, out_channels=num_classes, kernel_size=1)
def forward(self, image):
out_conv1 = self.down_conv_1(image)
out_pool1 = self.max_pool_2x2_1(out_conv1)
out_conv2 = self.down_conv_2(out_pool1)
out_pool2 = self.max_pool_2x2_2(out_conv2)
out_conv3 = self.down_conv_3(out_pool2)
out_pool3 = self.max_pool_2x2_3(out_conv3)
out_conv4 = self.down_conv_4(out_pool3)
# out_pool4 = self.max_pool_2x2_4(out_conv4)
# out_conv5 = self.down_conv_5(out_pool4)
# decoder part
# out_up_conv = self.up_conv_trans2(out_conv5)
# out_up_conv = self.up_conv_2(torch.cat([out_up_conv, out_conv4], 1))
out_up_conv = self.up_conv_trans3(out_conv4)
out_up_conv = self.up_conv_3(torch.cat([out_up_conv, out_conv3], 1))
out_up_conv = self.up_conv_trans4(out_up_conv)
out_up_conv = self.up_conv_4(torch.cat([out_up_conv, out_conv2], 1))
out_up_conv = self.up_conv_trans5(out_up_conv)
out_up_conv = self.up_conv_5(torch.cat([out_up_conv, out_conv1], 1))
out_up_conv = self.out(out_up_conv)
return out_up_conv
and here is my training code ![]()
import torch.nn.functional as F
import os
import torch.optim as optim
import numpy as np
from UNET_19classes import *
import random
from data_augmentation import transform
def check_nan(model, input):
output = model(input)
return torch.isnan(output).any()
# Sauvegarder le meilleur modèle
def save_model(epoch, model, optimizer, loss):
print(f"save final model")
torch.save({
'epoch': epoch,
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'loss': loss,
}, f'C:/Users/ne/Desktop/food-recognition/modele_sauvegarder/modele_{epoch}_{loss}.pth')
# Définition des classes
classes = ['background', 'bun', 'laitue', 'tomates', 'cheddar', 'hamburger',
'sauce', 'oignons', 'cornichon', 'fromage', 'poulet',
'fish', 'bacon', 'oeuf', 'oignon cuit', 'pomme de terre / frite',
'avocat', 'crevette', 'poulet pané/tenders', 'champignon']
# Convertir la liste de classes en un objet PyTorch Tensor
class_to_idx = {classes[i]: i for i in range(len(classes))}
idx_to_class = {i: classes[i] for i in range(len(classes))}
class_to_idx_tensor = torch.tensor(list(class_to_idx.values()))
# Définition du modèle UNet
model = UNet(num_classes=20)
# Charger les données d'entraînement et de test
train_source = np.load("images_burger_train_set.npy")
train_source = train_source[..., ::-1]
# train_source = train_source / 255.0
test_source = np.load("images_burger_test_set.npy")
train_target = np.load("mapped_masks.npy")
test_target = np.load("mapped_masks_test.npy")
# Mise aux dimensions correctes [N, C, H, W]
train_target = np.expand_dims(train_target, axis=3)
test_target = np.expand_dims(test_target, axis=3)
arr_zeros = np.zeros((156, 256, 256, 2))
arr_zeros2 = np.zeros((45, 256, 256, 2))
train_target = np.concatenate((train_target, arr_zeros), axis=-1)
test_target = np.concatenate((test_target, arr_zeros2), axis=-1)
# Définition de la fonction perte et de l'optimiseur
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# Paramètres généraux
num_epochs = 30
correct = 0
total = 0
# Entraînement sur CUDA du modèle
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.cuda()
# Boucle d'entraînement principale
for epoch in range(num_epochs):
# Phase d'entraînement
model.train()
batch_size = 12
train_acc = 0.0
# Paramètres d'entraînement
number_slice_trainset = list(range(156))
index_train = 0
number_batch_train = 156 // batch_size
random.shuffle(number_slice_trainset)
num_correct_train = 0
train_loss_array = []
train_accuracy_array = np.array([0])
train_loss = 0.0
# Paramètres de test
test_epoch_loss = 0
number_slice_testset = list(range(45))
index_test = 0
number_batch_test = 45 // batch_size
random.shuffle(number_slice_testset)
num_correct_test = 0
test_loss_array = []
test_accuracy_array = np.array([0])
best_test_loss = np.finfo(np.float32).max
val_loss = 0.0
# Boucle d'entraînement sur les lots/batch
for data in range(number_batch_train):
# Préparation des données
batch_train_source_numpy = train_source[number_slice_trainset[index_train:index_train + batch_size], :, :]
batch_train_source_numpy = np.transpose(batch_train_source_numpy, (0, 3, 1, 2))
batch_train_source_numpy = batch_train_source_numpy/255.0
batch_train_target_numpy = train_target[number_slice_trainset[index_train:index_train + batch_size], :, :]
batch_train_target_numpy = np.swapaxes(batch_train_target_numpy, 1, 3)
batch_train_target_numpy = np.swapaxes(batch_train_target_numpy, 2, 3)
batch_train_source_cuda = torch.tensor(batch_train_source_numpy).to(device=device, dtype=torch.float32)
batch_train_target_cuda = torch.tensor(batch_train_target_numpy).to(device=device, dtype=torch.float32)
batch_train_target_cuda = batch_train_target_cuda.cuda().float()
batch_train_target_cuda = torch.argmax(batch_train_target_cuda, dim=1)
result = transform(batch_train_source_cuda, batch_train_target_cuda)
batch_train_logits_cuda = model(result[0])
batch_prediction_cuda = torch.softmax(batch_train_logits_cuda, dim=1)
preds = batch_prediction_cuda.cpu().detach().numpy()
# Conversion des probabilités en indice de classe
preds_idx = np.argmax(preds, axis=1)
# Remplacement des noms de classes par les indices correspondants
names_for_each_pixel = preds_idx.astype(np.uint8)
loss = loss_function(batch_train_logits_cuda, batch_train_target_cuda)
loss.backward()
optimizer.step()
optimizer.zero_grad()
train_loss += loss.item()
index_train += batch_size
preds = F.softmax(batch_train_logits_cuda, dim=1).argmax(dim=1)
num_correct_train += (preds == batch_train_target_cuda).sum()
train_loss /= number_batch_train
print(f"epoch {epoch + 1}, train loss: {train_loss}")
train_acc = num_correct_train / ((torch.numel(batch_train_logits_cuda)) * number_batch_train)
# Test du modèle sur les données de validation
model.eval()
val_acc = 0.0
# Boucle de validation sur les lots
with torch.no_grad():
for data in range(number_batch_test):
batch_test_source_numpy = test_source[number_slice_testset[index_test:index_test + batch_size], :, :]
batch_test_source_numpy = np.swapaxes(batch_test_source_numpy, 1, 3)
batch_test_target_numpy = test_target[number_slice_testset[index_test:index_test + batch_size], :, :]
batch_test_target_numpy = np.swapaxes(batch_test_target_numpy, 1, 3)
batch_test_source_cuda = torch.tensor(batch_test_source_numpy).to(device=device, dtype=torch.float32)
batch_test_target_cuda = torch.tensor(batch_test_target_numpy).to(device=device, dtype=torch.float32)
batch_test_target_cuda = torch.argmax(batch_test_target_cuda, dim=1)
outputs = model(batch_test_source_cuda)
loss = loss_function(outputs, batch_test_target_cuda)
test_epoch_loss += loss
index_test += batch_size
val_loss += loss.item()
preds = F.softmax(outputs, dim=1).argmax(dim=1)
acc = (preds == batch_test_target_cuda).float().mean()
val_acc += acc.item()
test_epoch_loss /= number_batch_test
print(f"epoch {epoch + 1}, test loss: {test_epoch_loss}")
test_loss_array = np.append(test_loss_array, test_epoch_loss.item())
np.save(os.path.join(numpy_array_path, 'test_loss_array'), test_loss_array)