Hi everyone. I’m experimenting with UNet using Carvana Image Masking Dataset. I trained a model and I’m doing some inference with it. However predicted mask is very whitish and distorted. Here are the results:
The Actual Image:

Original Mask

Predicted Mask
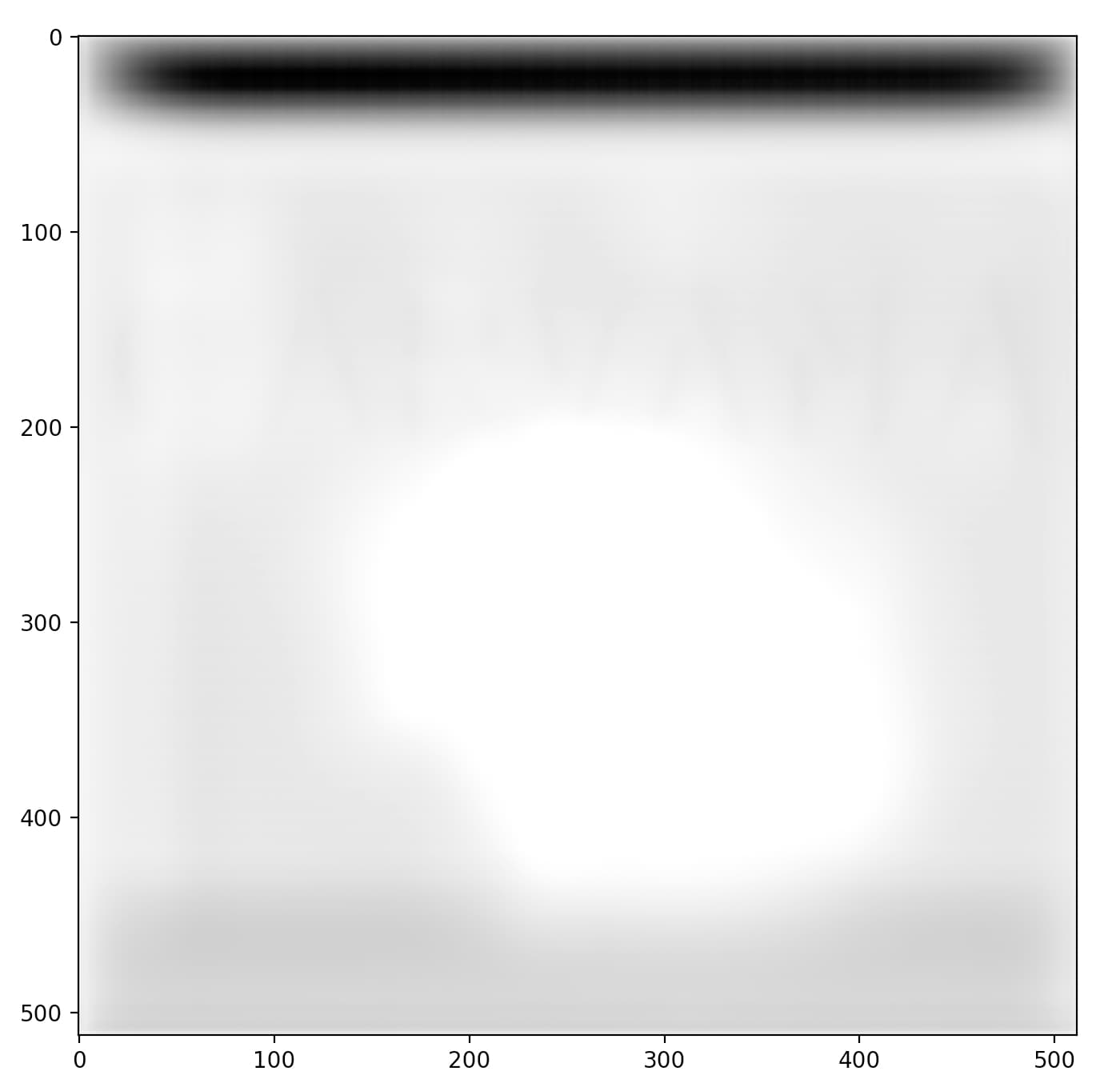
As you can see the supposed to be mask forms a whitish cluster at the “Predicted Mask” image. Still very distant from what it supposed to be.
Here is my dataset
import os
from PIL import Image
from torch.utils.data.dataset import Dataset
from torchvision import transforms
class CarvanaDataset(Dataset):
def __init__(self, root_path):
self.root_path = root_path
self.images = sorted([root_path+"/train/"+i for i in os.listdir(root_path+"/train/")])
self.masks = sorted([root_path+"/train_masks/"+i for i in os.listdir(root_path+"/train_masks/")])
self.transforms = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor()])
def __getitem__(self, index):
img = Image.open(self.images[index])
mask = Image.open(self.masks[index])
return self.transforms(img), self.transforms(mask)
def __len__(self):
return len(self.images)
Here is my training loop
model = UNet(3, 1).to(device)
optimizer = optim.AdamW(model.parameters(), lr=LEARNING_RATE)
criterion = nn.BCEWithLogitsLoss()
for epoch in tqdm(range(EPOCHS)):
model.train()
train_running_loss = 0
for idx, img_mask in enumerate(tqdm(train_dataloader)):
img = img_mask[0].float().to(device)
mask = img_mask[1].float().to(device)
y_pred = model(img)
optimizer.zero_grad()
loss = criterion(y_pred, mask)
train_running_loss += loss.item()
loss.backward()
optimizer.step()
train_loss = train_running_loss / idx+1
model.eval()
val_running_loss = 0
with torch.no_grad():
for idx, img_mask in enumerate(tqdm(val_dataloader)):
img = img_mask[0].float().to(device)
mask = img_mask[1].float().to(device)
y_pred = model(img)
loss = criterion(y_pred, mask)
val_running_loss += loss.item()
val_loss = val_running_loss / idx+1
print("-"*30)
print(f"Train Loss EPOCH {epoch+1}: {train_loss:.4f}")
print(f"Valid Loss EPOCH {epoch+1}: {val_loss:.4f}")
print("-"*30)
torch.save(model.state_dict(), MODEL_SAVE_PATH)
This is how I do inference
trained_model = UNet(3, 1)
trained_model.load_state_dict(torch.load("./models/unet.pth", map_location=torch.device(device)))
trained_model.eval()
img = train_dataset[1][0].float()
img = img.unsqueeze(0)
pred = trained_model(img)
print(pred.size())
mask = pred.squeeze(0).cpu().detach()
mask = mask.permute(1, 2, 0)
plt.imshow(mask, cmap="gray")
plt.show()
I thought there may be something wrong about how I do the image transformation. Specifically with how I transform images with Compose([transforms.Resize((512, 512)), transforms.ToTensor()]).
But I’ve seen other sources do the same. I can’t spot what is wrong. I would appreciate some help.