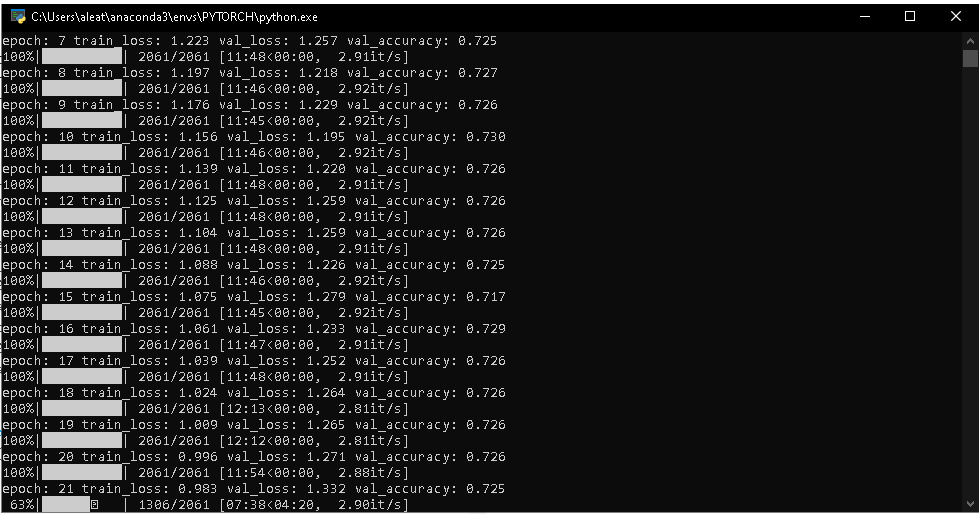
Hello everyone!
I’m trying to implement a UNET model for the PASCAL-VOC-2012 dataset. I made the code based on other codes I found here and in other forums, as I am a beginner in this area. After some adjustments I managed to make the code work, however, the validation loss does not decrease, and the accuracy remains stable around 0.7.
I’ve already split the dataset in different ways thinking it was overfitting (I only have 2913 masks for segmentation). But it didn’t.
I did the same with another dataset (Cityscapes), but nothing changed.
I made other attempts, but I’ve been working on this code for so long that I don’t even remember anymore. I can’t find the solution.
Please help me, I appreciate any attempt.
Train code:
import os
from unet import UNet
from unet_resnet import ResNetUNet
from fcn import FCN
from dataset import *
import torch
from torch.utils.data import DataLoader
from tqdm import tqdm
from torch.utils.data.sampler import RandomSampler
from torch import nn
import torchvision
from torchvision.transforms.transforms import Pad, Resize
from collections.abc import Sequence
from tensorboardX import SummaryWriter
#Mostra as versões do PyTorch e CUDA
print(f'PyTorch: {torch.__version__}')
print(f'CUDA: {torch.version.cuda}')
#Configura o melhor hardware disponível
if torch.cuda.is_available() == True:
device = "cuda"
print('GPU')
else:
device = "cpu"
print('CPU')
torch.multiprocessing.set_sharing_strategy('file_system') # ou file_descriptor
#Hiperparâmetros
# batch_size = 32 # for FCN
# batch_size = 8 # for res_unet
batch_size = 1
epoch = 30
taxaAp = 1e-3
#Nome do modelo a ser salvo
weight_name = 'modelo_FCN'
#Redes disponíveis para uso
#salt = ResNetUNet(21)
#salt = FCN(21)
salt = UNet(21)
salt.to(device)
#Função de perda
criterion = nn.CrossEntropyLoss(ignore_index=255)
#otimizador
optimizer_ft = torch.optim.Adam(filter(lambda p: p.requires_grad, salt.parameters()), lr=taxaAp)
#Diminui a taxa de aprendizado se o modelo não convergir
exp_lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer_ft, step_size=30, gamma=0.1)
#Pré-processamento de imagens
class ResizeSquarePad(Resize, Pad):
def __init__(self, target_length, interpolation_strategy):
if not isinstance(target_length, (int, Sequence)):
raise TypeError("Deve ser inteiro ou uma sequencia. Obtido {}".format(type(target_length)))
if isinstance(target_length, Sequence) and len(target_length) not in (1, 2):
raise ValueError("Se for uma sequencia deve ter 1 ou 2 valores")
self.target_length = target_length
self.interpolation_strategy = interpolation_strategy
Resize.__init__(self, size=(512, 512), interpolation=self.interpolation_strategy) #Redimensionamento
Pad.__init__(self, padding=(0,0,0,0), fill=255, padding_mode="constant") #Contorna com zeros
#Calcula o redimensionamento e padding
def __call__(self, img):
w, h = img.size
if w > h:
self.size = (int(np.round(self.target_length * (h / w))), self.target_length)
img = Resize.__call__(self, img)
total_pad = self.size[1] - self.size[0]
half_pad = total_pad // 2
self.padding = (0, half_pad, 0, total_pad - half_pad)
return Pad.__call__(self, img)
else:
self.size = (self.target_length, int(np.round(self.target_length * (w / h))))
img = Resize.__call__(self, img)
total_pad = self.size[0] - self.size[1]
half_pad = total_pad // 2
self.padding = (half_pad, 0, total_pad - half_pad, 0)
return Pad.__call__(self, img)
#Faz várias transformações de uma única vez
transform_img = torchvision.transforms.Compose([
ResizeSquarePad(512, Image.BILINEAR), #Chama a func. de redimensionamento
torchvision.transforms.ToTensor(), #Converte para GPU
torchvision.transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225]) #Normaliza a image conforme a média e desvio descritos
])
transform_mask = torchvision.transforms.Compose([
ResizeSquarePad(512, Image.NEAREST) #Chama a func. de redimensionamento, precisa usar NEAREST para manter o rótulo dtype como int.
])
#Carrega os diretórios
train_image_dir = "DATASET/train/"
val_image_dir = "DATASET/val/"
#Função que carrega os dados de treino, teste e validação
X_train, y_train = trainImageFetch(train_image_dir)
X_val, y_val = valImageFetch(val_image_dir)
#Define o modo (treino ou teste) e transforma as imagens/máscaras
train_data = SegDataset(X_train, y_train, 'train', transform_img, transform_mask)
val_data = SegDataset(X_val, y_val, 'val', transform_img, transform_mask)
#Carrega as imagens de forma aleatória em lotes de "batch_size"
train_loader = DataLoader(train_data,
shuffle=RandomSampler(train_data),
batch_size=batch_size)
val_loader = DataLoader(val_data,
shuffle=False,
batch_size=batch_size)
#Treino
def train(train_loader, model):
running_loss = 0.0
data_size = len(train_data) #define a qtd. de amostras do dataset
model.train() #coloca o modelo no modo de treino
#A rede vê cada amostra de imagens e máscara para aprender
for inputs, masks in tqdm(train_loader):
inputs, masks= inputs.to(device), masks.long().to(device)
optimizer_ft.zero_grad() #Zera os gradientes
logit = model(inputs)
loss = criterion(logit, masks.squeeze(1)) #Converte os dados para um array 1D
loss.backward() #Calcula a variação da perda para cada entrada
optimizer_ft.step() #Atualiza os parâmetros
running_loss += loss.item() * batch_size #Perda acumulada
epoch_loss = running_loss / data_size #Perda por época
return epoch_loss
#Teste
def test(test_loader, model):
running_loss = 0.0
acc = 0.0 #Acurácia
data_size = len(test_loader) #Qtd. de amostras
model.eval() #Modo de teste
with torch.no_grad(): #Por ser teste não requer gradiente
for inputs, masks in test_loader:
inputs, masks = inputs.to(device), masks.long().to(device)
outputs = model(inputs)
predict = torch.argmax(nn.Softmax(dim=1)(outputs), dim=1) #Resultado da predição
pure_mask = masks.masked_select(masks.ne(255)) #Valores diferentes de 255 na máscara (Branco)
pure_predict = predict.masked_select(masks.ne(255)) #Valores diferentes de 255 na predição
acc += pure_mask.cpu().eq(pure_predict.cpu()).sum().item()/len(pure_mask) #Calcula a acurácia
loss = criterion(outputs.squeeze(1), masks.squeeze(1)) #Calcula a perda
running_loss += loss.item() * inputs.size(0) #Calcula a perda acumulada
epoch_loss = running_loss / data_size #Perda por época
accuracy = acc / data_size #Acurácia no dataset
return epoch_loss, accuracy
best_acc = 0
writer = SummaryWriter("./log/UNet")
#Escreve um log com os resultados obtidos
for epoch_ in range(epoch):
train_loss = train(train_loader, salt)
val_loss, accuracy = test(val_loader, salt)
exp_lr_scheduler.step()
writer.add_scalar('loss/train', train_loss, epoch_)
writer.add_scalar('loss/valid', val_loss, epoch_)
writer.add_scalar('accuracy', accuracy, epoch_)
if accuracy > best_acc:
best_acc = accuracy
best_param = salt.state_dict()
print('epoch: {} train_loss: {:.3f} val_loss: {:.3f} val_accuracy: {:.3f}'.format(epoch_ + 1, train_loss, val_loss, accuracy))
torch.save(salt.state_dict(), weight_name + '_%d.pth' % epoch_)
writer.close()
Unet:
import torch
import torch.nn as nn
down_feature = []
filter_list = [i for i in range(6, 9)]
class down_sampling(nn.Module):
def __init__(self, in_channel, out_channel):
super(down_sampling, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channel, out_channel, 3, padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True),
nn.Conv2d(out_channel, out_channel, 3, padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True)
)
self.pool = nn.MaxPool2d(2)
def forward(self, in_feat):
x = self.conv(in_feat)
down_feature.append(x)
x = self.pool(x)
return x
class up_sampling(nn.Module):
def __init__(self, in_channel, out_channel):
super(up_sampling, self).__init__()
self.up_conv = nn.ConvTranspose2d(in_channel, out_channel, 2, stride=2)
self.relu_conv = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True),
nn.Conv2d(out_channel, out_channel, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True)
)
def forward(self, in_feat):
x = self.up_conv(in_feat)
down_map = down_feature.pop()
x = torch.cat([x, down_map], dim=1)
x = self.relu_conv(x)
return x
class UNet(nn.Module):
def __init__(self, num_classes):
super(UNet, self).__init__()
self.input_conv = down_sampling(3, 64)
self.down_list = [down_sampling(2 ** i, 2 ** (i + 1)) for i in filter_list]
self.down = nn.Sequential(*self.down_list)
self.last_layer = nn.Sequential(
nn.Conv2d(512, 1024, 3, padding=1),
nn.BatchNorm2d(1024),
nn.ReLU(inplace=True),
nn.Conv2d(1024, 1024, 3, padding=1),
nn.BatchNorm2d(1024),
nn.ReLU(inplace=True)
)
self.up_init = up_sampling(1024, 512)
self.up_list = [up_sampling(2 ** (i + 1), 2 ** i) for i in filter_list[::-1]]
self.up = nn.Sequential(*self.up_list)
self.output = nn.Conv2d(64, num_classes, 1)
# self.classifier = nn.Softmax()
def forward(self, in_feat):
x = self.input_conv(in_feat)
x = self.down(x)
x = self.last_layer(x)
x = self.up_init(x)
x = self.up(x)
x = self.output(x)
# out = self.classifier(x)
# return out
return x